
Coding with Streams(使用流编程)
Discovering the importance of streams(流的重要性)
Buffering versus streaming(缓存 vs 流)
Buffering:等到所有数据都收集完了才发送给消费者。Streaming:实时发送数据到消费者。
我们从几个方面来对比这两种方式:
Spatial efficiency(空间效率)
当我们需要去读一个非常大的文件时,比方说数百 MB 或 GB,如果等到文件全部读取完了再返回一个巨大的 buffer 就会很快耗尽内存,在 V8 中 buffer 最大不能超过 0x3FFFFFFF(比 1GB 略小)。
在 64 位系统中,
buffer的最大大小为2^31 - 1(约 2GB),书中默认是 32 位系统了,详情可查看官方文档给出的buffer.constants.MAX_LENGTH。
Gzipping using a buffered API(使用缓冲 API 压缩)
使用下面代码读一个非常大的文件:
1 | const fs = require('fs') |
1 | node gzip <big file path> |
会抛出异常,RangeError: File size is greater than possible Buffer:0x7FFFFFFF。
Gzipping using streams(使用流压缩)
使用流 API 来压缩就没有上面的问题了:
1 | const fs = require('fs') |
Time efficiency(时间效率)
考虑一个压缩文件并将该文件上传到远程服务器的例子,如果使用 buffer 来实现,那么就需要等待文件全部读完才能开始上传,服务器也要等到完全接收完才能进行下一步处理,这很明显就浪费了很多时间去等待上一步任务的完成,使用 stream 来处理则没有这些瓶颈,可以一步步处理一个数据块而不是全部的数据,代码如下:
1 | // file gzipReceive.js |
使用 stream 更像是流水线,我们用一张图来说明这个问题:
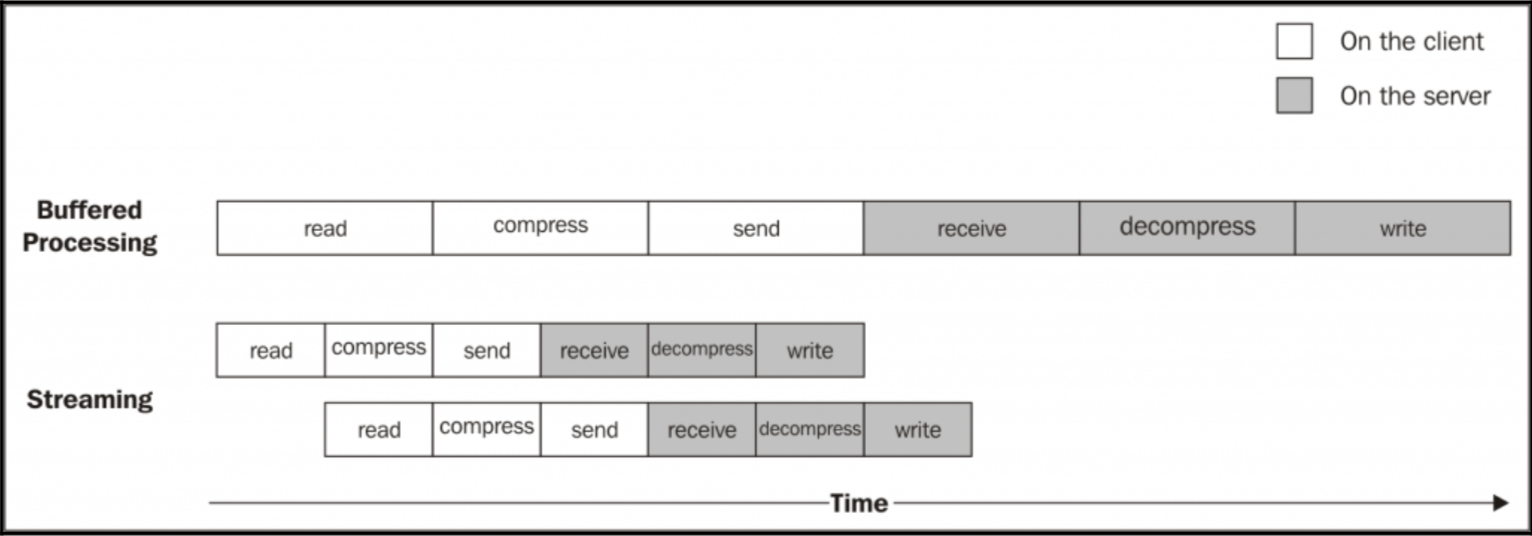
一个文件被处理的过程,它经过以下阶段:
- 客户端从文件系统中读取
- 客户端压缩数据
- 客户端将数据发送到服务器
- 服务端接收数据
- 服务端解压数据
- 服务端将数据写入磁盘
当我们使用 Streams 时,只要我们收到第一个数据块,流水线就会被启动,而不需要等待整个文件的读取。当有多个块时,就会有多条流水线,每个操作又是异步的,完成任务的顺序就变得不确定了,所以需要保证的就是每个阶段数据块的到达顺序了(还好Node.js 的流已经帮我做好了这件事了)。
总结:使用 stream 的时间效率也要更高。
Composability(组合型)
其实从前面的代码就可以看到,通过 pipe 函数可以很方便的组合处理函数,也就是使用了我们所熟知的 Pipe-Fillter 模式。
这种模式可以很方便地组合过滤器,使得代码更加清晰,便于维护,同时也加强了功能模块的复用。
Getting started with streams(开始使用 streams)
Anatomy of streams(流的结构)
Node.js 中的流都是下面四种抽象类的实现:
- stream.Readable
- stream.Writable
- stream.Duplex(同时 Readable 和 Writable)
- stream.Transform(Duplex 的扩展)
每个流同时也是 EventEmitter 的一个实例。实际上 Streams 可以产生几种类型的事件,比如 end 事件会在一个可读的 Streams 完成读取后触发,或者 error 事件在出现错误时触发。
注意在生产环境中最好为
Stream注册错误事件的监听。
Stream 支持两种操作模式:
- 二进制模式:以数据块形式(例如
buffers或strings)流式传输数据 - 对象模式:将流数据视为一系列离散对象(这使得我们几乎可以使用任何
JavaScript值)
Readable streams(可读的流)
一个可读的 Streams 表示一个数据源,在 Node.js 中,它使用 stream 模块中的 Readable 抽象类实现。
Reading from a stream(从一个流中读数据)
从可读 Streams 接收数据有两种方式:non-flowing(paused) 模式和 flowing 模式。
The non-flowing mode(paused)
从可读的 Streams 中读取数据的默认模式是为其附加一个可读事件侦听器,标识已经有数据可以读了。
然后,在一个循环中,我们读取所有的数据,直到内部 buffer 被清空。这可以使用 read() 方法完成,该方法同步从内部缓冲区中读取数据,并返回表示数据块的 Buffer 或 String 对象。然后,在一个循环中,我们读取所有的数据,直到内部 buffer 被清空。这可以使用 read() 方法完成,该方法同步从内部缓冲区中读取数据,并返回表示数据块的 Buffer 或 String 对象。
1 | process.stdin |
read() 方法是一个同步操作,它从可读 Streams 的内部 Buffers 区中提取数据块。如果 Streams 在二进制模式下工作,返回的数据块默认为一个 Buffer 对象。当没有数据消费时,read() 会返回 undefined。
我们也可以尝试将我们的程序与其他程序连接起来;这可以使用管道运算符(|),它将程序的标准输出重定向到另一个程序的标准输入:
1 | cat <path to a file> | node readStdin |
The flowing mode
另外一种读取流的方式是使用流动模式,给 data 事件添加一个监听,这种模式是一有数据就会推送到这个监听器中:
1 | process.stdin |
flowing 模式是旧版 Streams 接口(也称为 Streams1)的继承,这里补充一下从 Stream1 到 Stream3 的比较:
从 Stream1 到 Stream3
- Stream1 推流
在最初的流实现中,每次当有数据可用时,都有一个数据事件发生,开发者可以使用 pause() 和 resume() 来控制流,调用 pause() 将引起底层停止发送数据事件的发生。
存在的问题:
- 暂停
pause()方法并不暂停,它只是建议advisory-only。 - 无论你是否准备好,’数据’ 事件就立即来了。
- 没有办法消费使用指定数量的字节,然后将剩余的交给程序其他部分来处理。
- Stream2 拉流
Node 0.10 引入了 Stream2,增加了 Pull 拉方式,也就是从数据流读取时可以采取拉方式,这样解决了以前的问题,流总是从暂停状态开始,通过 read(numBytes) 读取,此外,当数据可用时,一个可读的事件将被触发。
Stream2 预设模式就是拉方式也就是非流动模式,想要转回流动模式只要给 data 事件加上监听就行了。
注意:Flowing/Non-flowing 模式只能择一使用。也就是
data和readable事件监听只能有一个,虽然二者同时监听程序也不会挂掉,但是还是会出现预期之外的现象。
- Stream3 混合流
可以看看官方文档对现在可读流的描述。
从 Node 0.12 开始,Stream 就已经使用这种方式了,可以在 flowing 模式和 paused 模式之间切换,延续至今。
Readable 流初始为 paused 模式,有以下行为会转为 flowing 模式:
- 添加
data事件监听 - 调用
stream.resume() - 调用
stream.pipe()将数据发送到一个Writable Stream
使用下面某一种方法可以切换回 paused 模式:
- 如果没有定义过管道,直接调用
stream.pause() - 如果有管道定义过,必须先删除所有管道,
注意:移除
data事件的监听并不会自动切回paused模式;如果还有管道没有被移除,调用stream.pause()也不能保证就是paused模式。
注意:在
flowing模式下如果没有消费者消费数据,那么数据会丢失。举个例子:调用readable.resume时没有绑定data事件或该事件已被移除,这样数据就丢失了。
推荐使用 stream.pipe() 来处理,这种方式是比较容易处理流数据的。
Implementing Readable streams(实现可读流)
需要实现 _read([size]) 方法,push() 方法将数据放到缓冲区:
1 | const stream = require('stream') |
Writable streams(可写流)
一个可写的 stream 表示一个数据目标点,在 Node.js 中,它使用 stream 模块中的 Writable 抽象类来实现。
Writing to a stream
writable.write(chunk, [encoding], [callback]) 写数据。
writable.end([chunk], [encoding], [callback]) 表示没有更多的数据写入了,也就是流的结束,这种情况 callback 相当于给 finish 事件加了个监听。
Back-pressure(回压)
当写入数据比消费该数据要快时,可以先缓冲数据,如果超过某个限制就需要通知 writer 不能再写了。
内部 buffer 超过 highWaterMark 的限制时,write() 方法会返回 false。
看一个使用例子:
1 | const Chance = require('chance') |
注意当
write()返回false时,跳出函数,等到队列释放后,Writable Stream会触发一个drain事件,这时候再继续启动写入程序继续写入数据。
Implementing Writabel streams(实现可写流)
实现可写流需要实现 _wirte() 方法。
让我们构建一个可写入的 stream,它接收对象的格式如下:
1 | { |
对于每一个对象,我们的 stream 必须将 content 部分保存到在给定路径中创建的文件中。 我们可以立即看到,我们 stream 的输入是对象,而不是 Strings 或 Buffers,这意味着我们的 stream 必须以 对象模式 工作。
1 | const stream = require('stream') |
传入 options 为 {objectMode: true} 设置可写流为 对象模式,接收的其他选项如下:
highWaterMark(默认值是16KB):控制back-pressure的上限。decodeStrings(默认为true):在字符串传递给_write()方法之前,将字符串自动解码为二进制buffer,在对象模式下这个参数被忽略。
Duplex streams(复用流,同时可写可读)
同时实现 stream.Readable 和 stream.Writable。
options 和上文提到的都一样,有一个额外的选项 allowHalfOpen (默认是 true),如果设置为 false 那么当读/写一方关闭时,整个都会关闭。
常见的 Deplex Stream 就是 net 的 Socket。
Transform streams(转换流)
转换流是复用流的扩展,在同时实现了 Readable 和 Writable 的基础上,加了一层转换,
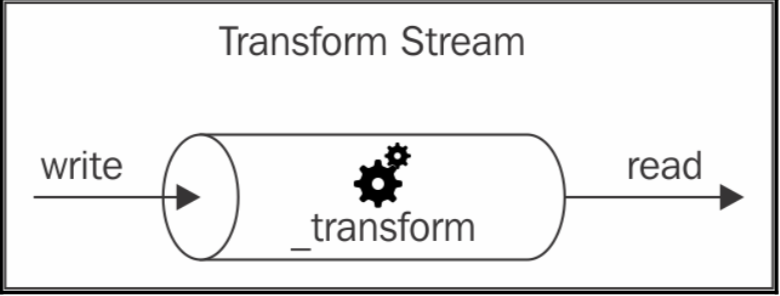
Implementing Transform streams(实现转换流)
我们来实现一个 Transform Stream,它将替换给定所有出现的字符串。
1 | // file replaceStream.js |
1 | const ReplaceStream = require('./replaceStream') |
上面代码的思路是将新来的数据块与上次处理后剩下的数据(最大长度为搜索字符串长度减 1,这样长度的字符串是不可能包含搜索字符串的,保证前面的出现的搜索字符串已被处理完)拼接起来,按照搜索字符串分割,最后一片除掉尾部搜索字符串长度减 1 长度的字符串,然后重新拼接处理后的字符串 pieces.join(this.replaceString),再 push 进可读流,这里是触发 data 事件。
Connecting streams using pipes(使用管道连接流)
readable.pipe(writable, [options]),使用管道连接了 Readable Stream 和 Writable Stream,很显然,pipe() 方法将从 Readable Stream 中发出的数据抽取到所提供的 Writable Stream 中,该方法返回作为参数提供的 writable。
将两个 Streams 连接到一起时,则允许数据自动流向 Wratable Stream,所以不需要调用 read() 或 write() 方法;但最重要的是不需要控制 back-pressure,因为它会自动处理。
举例:
1 | const ReplaceStream = require('./replaceStream') |
注意:error 事件不会通过管道自动传播。也就是说
1 | stream1.pipe(stream2).on('error', function() {}) |
是不会监听到
stream1的错误的,要想监听stream1的错误只能另外加一个监听函数。
Through and form for working with streams(through 和 form 库)
总是去自定义一个流是比较繁琐的,这里提供两个库能简单地创建流:
1 | const transform = through2([options], [_transform], [_flush]) |
Asynchorous control flow with streams(使用流的异步控制流)
Sequential execution(顺序执行)
默认情况 stream 是顺序处理数据的,这是 Stream 的一个重要属性,可以利用这个属性实现传统的异步控制流:
1 | const fromArray = require('from2-array') |
- 首先从文件数组创建
Readable Stream。 - 创建
Transform Stream来处理每个文件,对于每个文件创建一个Readable Stream,通过管道将读取的数据传递给目标Writable Stream,指定第二个参数end为false确保处理完每个文件后Writable Stream不会被关闭。 - 所有文件处理完后,触发
finish事件,关闭Writable Stream,调用concatFiles的callback。
Unordered parallel execution(无序并行执行)
有时候数据块之间没有任何关系,这时候可以并行执行异步任务,这通常发生在 对象模式 中,而对于 二进制模式 流是非常罕见的。
Implementing an unordered parallel stream(实现无序并行流)
1 | const stream = require('stream') |
这个同步执行流接收一个 userTransform 作为参数,这个是用户规定的异步转换流(用来真实处理流数据的),_transform() 函数中不用等待 userTransform() 执行完成,直接执行 done() 通知改转换已完成,另一方面将 this._onComplete() 传递给 userTransform(),使得在真正的处理完成后调用 this._onComplete()。
在 Stream 终止前会调用 _flush() 方法,如果这个时候还有异步任务在执行(running > 0)那么将会持有 done 的引用,等到所有异步任务完成调用 this._onComplete() 回调函数时才会调用真实的 done 方法即 this.terminateCallback,调用后会结束 Stream,触发 finish 事件。
Implementing a URL status monitoring application(实现一个 URL 状态监听应用)
看一个使用上面实现的 Paralle Stream 的一个例子:
1 | const fs = require('fs') |
- 首先,我们通过给定的文件参数创建一个可读的
Streams,便于接下来读取文件。 - 我们通过
split将输入的文件内容输出到一个Transform Stream管道中,并且将数据的每一行分成不同的块。 - 然后,使用
ParallelStream来检查URL,我们发送一个HEAD请求然后等待请求的response。当请求返回时,我们把请求的结果push到stream中。 - 最后,通过管道把结果保存到
results.txt文件中。
Unordered limited parallel execution(无序限制并行执行)
和第三种中异步控制流实现限制并行执行一样,改变 _transform 如下:
1 | this.running++ |
_flush 方法保持不变,更改 _onComplete 方法如下:
1 | _onComplete(err) { |
从上面可以看出,调用 _transform 需要检查是否达到最大执行任务数,达到则不会立即调用 done,即流处理会阻塞在那里,直到正在执行的任务中某一个结束调用 _onComplete 才会执行 done,这样才能继续处理下一个 chunk。
Ordered parallel execution(有序并行执行)
对接收顺序有要求的场景下仍然可以使用并行执行,只不过需要对每个任务发出的数据排序(和接收到数据的顺序一致),这里不再累述,可以使用第三方库 throught2-parallel。
Piping patterns(管道模式)
Combining streams(组合流)
单个 Stream 使得我们可以复用一条流,那当我们想要复用整条流水线时怎么办,即合并多个 Stream 使得看起来是一整个 Stream,如下图:
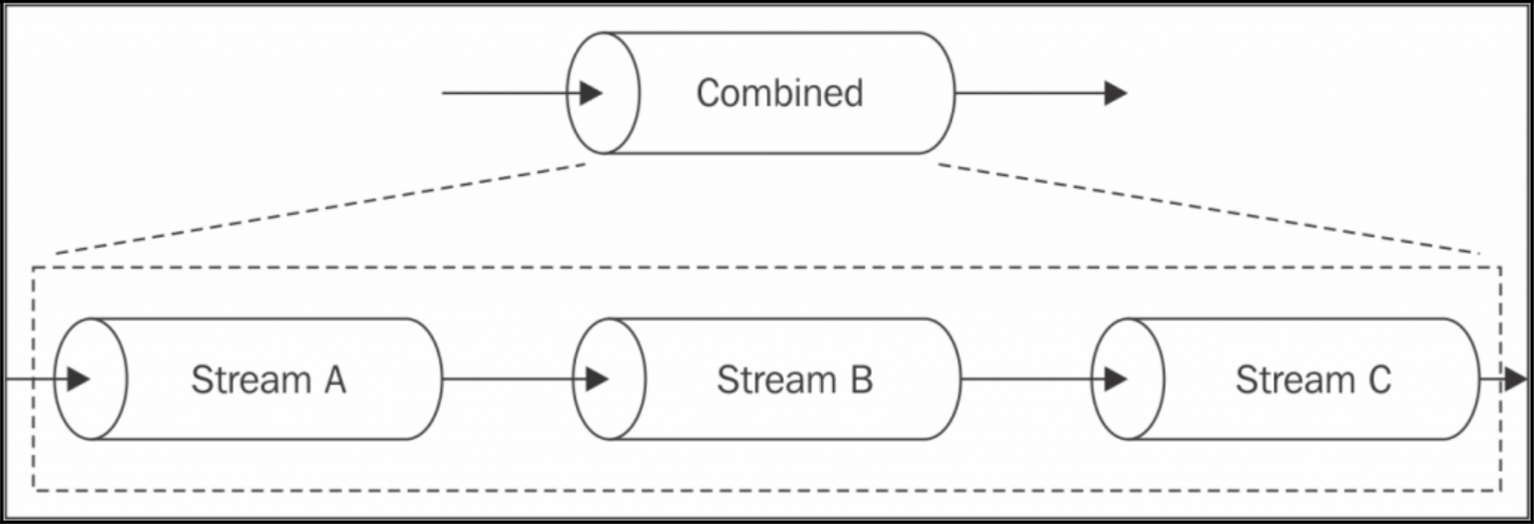
从图中可以看出,组合流其实就是 写入第一个流,然后从最后一个流读。
一个组合流通常是一个 Duplex Stream,通过连接第一个流到写入端和连接最后一个流到读取端构建这个复用流。
我们知道错误在管道中是不能冒泡出去,这就意味着我们得为每一个流都添加一个错误监听,然而组合流实际上是个黑盒,作为一个流错误的聚合器。
总之,组合流有两个优点:
- 管道内部是一个黑盒,对使用者不可见。
- 简化了错误管理,因为我们不必为管道中的每个单元附加一个错误侦听器,而只需要给组合流自身附加上就可以了。
组合流是非常普遍的用法,所以已经有现成的库做了这些封装了,可以看看 multipipe 或 combine-stream。
Implementing a combined stream(实现一个组合流)
看一个例子:
1 | const zlib = require('zlib') |
一个组合流是压缩并加密,一个组合流是解密并解压。
注意:
compressAndEcrypt或decryptAndDecompress直接监听error事件是能监听整个流水线中的任何流错误的,这要得益于组合流的黑盒模式了。
Forking streams(分流)
我们可以通过将一个 Readable Stream 用管道传输给多个 Writable Stream 来达到分流的目的。
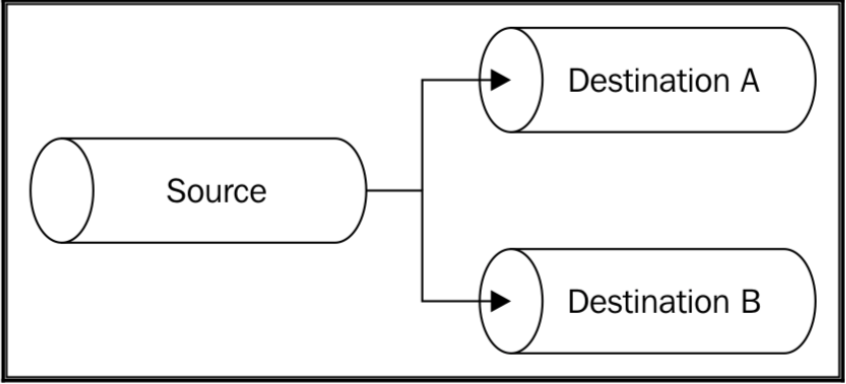
Implementing a multiple checksum generator(实现一个多重检验生成器)
创建一个工具类用来输出给定文件的 md5 和 sha1 的 hash 值。
1 | const fs = require('fs') |
需要注意的是:
当
inputStream结束时,md5Stream和sha1Stream会自动结束,除非当调用pipe()时指定了end选项为false。Stream的两个分支会接受相同的数据块,因此当对数据执行一些副作用的操作时我们必须非常谨慎,因为那样会影响分流的另一个分支。黑盒外会产生回压,来自
inputStream的数据流的流速会和接收最慢的分支的流速相同。
Merging streams(合并流)
合并流和分流相对,是将多个 Readable Stream 通过管道输入到一个 Writable Stream 中。
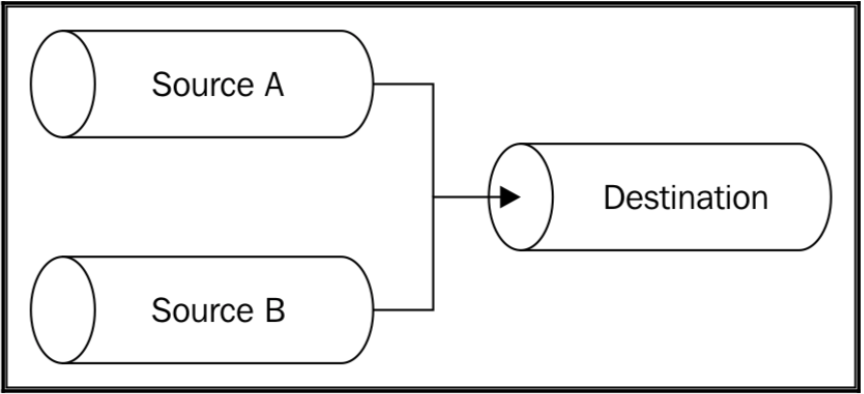
这是一个比较简单的操作,唯一需要注意的是 Writable Stream 的关闭,选项 end 需要设置为 false,否则在一个输入流结束后,写入流也就跟着结束了,尽管另一个输入流还没处理完,需要在所有输入流都被读过之后才能调用 end() 方法。
Creating a tarball from multiple directories(从多个文件夹创建压缩包)
1 | var tar = require('tar') |
两个源文件通过 pack 压缩到一个流中: node mergeTar dest.tar /path/to/sourceA /path/to/sourceB。
这种合并是无顺序的,这在某些对象流中是可以接收的,但是二进制流通常就不行了。
合并流还有一种变种,是按顺序合并流的,一个接一个地合并源 Stream,当前一个结束时,开始发送第二段数据块(就像连接所有源 Stream 的输出一样)。有个 npm 的包 multistream 可以处理这种场景。
Multiplexing and demultiplexing(多路复用和多路分解)
合并流的一种特殊情况是保持各个流在一个共享流中是逻辑分离的,等到到达共享流的出口时又重新分流,这就是多路复用和多路分解:
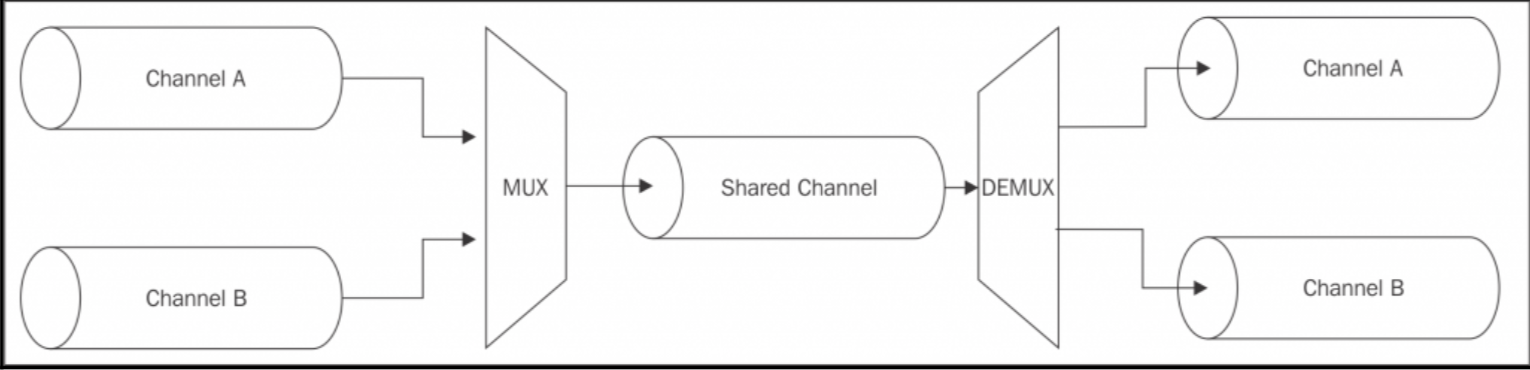
Building a remote logger(创建一个远程日志记录器)
假设我们需要将一个程序的标准输出和标准错误都重定向到一个远程服务器,服务器接收后存为两个文件,共享通道是 TCP 连接,需要多路复用的两个渠道是 stdout 和 stderr,我们利用一个叫做 分组交换 的技术将数据打包进包中,协议大概是这样,数据被封装成具有以下结构的数据包:
1 | 1 byte Channel ID | 4 bytes Data length | Data |
客户端——多路复用
1 | const child_process = require('child_process') |
可以发现 multiplexChannels() 方法接收多个源,监听每个源,使用 non-flowing(paused) 模式读取流数据,写入包结构(Channel ID 为流在源数组中的下标),然后都往远程流中写数据,完成多路复用。
1 | // 客户端代码 |
服务端——多路分解
1 | function demultiplexChannel(source, destinations) { |
- 我们开始使用
non-flowing(paused) 模式从流中读取数据。 - 首先,如果我们还没有读取
Channel ID,我们尝试从流中读取 1 个字节,然后将其转换为Channel ID。 - 下一步是读取数据块的长度。我们需要读取 4 个字节,所以有可能在内部
Buffer还没有足够的数据,这将导致this.read()调用返回null。在这种情况下,我们只是中断解析,然后重试下一个readable事件。 - 当知道了数据长度后,就知道要从内部
Buffer中拉出多少数据了,所以我们尝试读取所有数据。 - 当我们读取所有的数据时,我们可以把它写到正确的目标通道,一定要记得重置
currentChannel和currentLength变量(这些变量将被用来解析下一个数据包)。 - 最后,当所有的源流结束时,一定不要忘记调用所有目标流的
end()方法来结束目标流。
1 | // 服务端代码 |