
Wiring Modules(连接模块)
对模块常见的一个问题就是:将组件 X 的实例传递到模块 Y 的最佳方式是什么?
常见的模式有一下几种:
- 硬编码依赖
- 依赖注入
- 服务定位器
- 依赖注入容器
Modules and dependencies(模块和依赖)
The most common dependency in Node.js(Node.js 中最常见的模块)
一个模块的属性可以概括如下:
- 一个模块应该具有可读性和可理解性,因为它应该专注于一件事。
- 一个模块被表示为一个单独的文件,使得其更容易被识别。
- 模块可以更容易地在不同的应用程序中复用。
Cohesion and coupling(内聚和耦合)
评判创建的模块平衡性两个最重要的特征就是内聚度和耦合度。这两个特征可以应用于软件体系结构中的任何类型的组件或子系统。因此在构建 Node.js 模块时也可以把这两个特征作为重要的参考价值。这两个属性定义如下:
内聚度:用于度量模块内部功能之间的相关性。例如,对于一个只做一件事的模块,其中的所有部件都只对这一件事起作用,那说明这个模块具有很高的内聚度。举个例子,那种包含把任何类型的对象存储到数据库的函数内聚度就较低,如 saveProduct()、saveInvoice()、saveUser() 等。
耦合度:评判模块对系统其他模块的依赖程度。例如,当一个模块直接读取或修改另一个模块的数据时,该模块与另一个模块是紧密耦合的;另外,通过全局或共享状态交互的两个模块也是紧密耦合的;另一方面,仅通过参数传递进行通信的两个模块耦合度较低。
理想情况下,一个模块应该具有较高的内聚度和较低的耦合度,这样的模块更易于理解、重用和扩展。
Stateful modules(有状态的模块)
在 JavaScript 中,将接口与实现分离的例子很少。 然而,通过使用 Node.js 模块系统,我们引入了一个特定的模块,接口不会受到其它模块的影响。在正常情况下,这没有什么问题,但是如果我们使用 require() 来加载一个导出有状态实例的模块,比如数据库交互对象,HTTP 服务器实例,乃至普通的任何对象这不是无状态的,我们实际上是在引用的模块都是一个又一个的单例,因此模块系统有着单例模式的优点和缺点,此外,也有一些不同的地方。
The Singleton pattern in Node.js(Node.js 中的单例模式)
在 Node.js 中其实单例很简单,在 export 的过程中就完成了:
1 | //'db.js' module |
因为在第一次 require 之后就会把模块缓存下来,之后只会返回缓存的实例。但是这不是一定是单例的,有可能有多个包都含有这个 db 依赖,那么就会有多个实例出来,例如这样的依赖结构:
1 | app/ |
这个时候可以赋予实例给全局变量来达到真正单例的效果(通常不这么做,这是比较危险的)。
Patterns for wiring modules(连接模块的模式)
Hardcoded dependency(硬编码依赖)
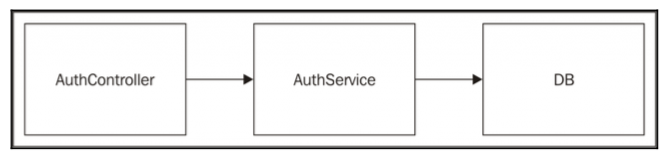
从图中可以发现,硬编码依赖就是一层层依赖下来,从模块中直接导出有状态的实例,最原始的方案。
优点:管理起来非常直观,易于理解和调试,每个模块初始化和引入,都不会受到任何外部条件的干预。
缺点:限制将模块与其他实例关联的可能性,这使得在单元测试的过程中,其可重用性更低,测试难度更大。
Dependency injection(依赖注入)
依赖注入模式背后的主要思想是由外部实体提供输入的组件的依赖关系。这样的实体可以是客户端组件或全局容器,它集中了系统所有模块的关联。这种方法的主要优点是解耦,特别是对于取决于有状态实例的模块。
可以使用工厂来创建有状态的实例,然后将实例注入组件:
1 | const Express = require('express') |
当然还有其他注入的方式,比如构造函数注入和属性注入。
构造函数注入:
1 | const service = new Service(dependencyA, dependencyB) |
属性注入:
1 | const service = new Service() |
注意属性注入会导致实例的不一致状态,创建时的初始状态和设置依赖后的状态。但是当存在依赖循环时就很有用了,比如有两个组件
A和B,它们都使用工厂或构造函数注入,并且都相互依赖,我们不能实例化它们中的任何一个,因为两者都需要另一个存在才能被创建。
举个例子:
1 | function Afactory(b) { |
依赖倒置通常还会提到
DIP(Dependency Inversion Principle,依赖倒置原则) 和IoC(Inversion of Control,控制反转)。依赖倒置就是原来都是高层组件依赖底层组件,针对不同的底层组件实现不同的接口,倒置就是定义好高层组件的接口,而让底层组件去实现接口,这样当新加了底层组件的时候就不用修改高层组件的代码了。控制反转一种重要的方式,就是将依赖对象的创建和绑定转移到被依赖对象类的外部来实现,就像上面的代码一样authService需要依赖db那么这个建立依赖的过程却交给authController来处理了,这样能很好地将Service与DB解耦。
Service locator(服务定位器)
服务定位器核心原则是拥有一个中央注册中心,以便管理系统组件,并在模块需要加载依赖时作为中介,但是要求连接的是使用依赖注入的模块。
1 | module.exports = () => { |
想要更换依赖只需要更改注册的实例或者工厂函数即可,之后便可通过 get(name) 来获得定制好的对应实例。这里还可以将这些参数写成配置,那么就可以不动代码只改写配置就能完成依赖的替换了。
服务定位器惰性加载模块。每个实例仅在需要时创建。还有另一个重要的含义:事实上,我们可以看到,每个依赖关系都是自动连接的,无需手动完成。好处是我们不必事先知道实例化和连接模块的正确顺序是什么 - 这一切都是自动和按需进行的。与简单的依赖注入模式相比,这更方便。
与依赖注入的区别:
- 可重用性:依赖于服务定位器的组件不易重用,因为它要求系统中有一个服务定位器。
- 可读性:正如我们已经说过的,服务定位器混淆了组件的依赖性要求。
Dependency injection container(依赖注入容器)
和服务定位器十分类似,只不过不用传递 locator 对象到模块中,而是通过某些手段(如参数名,导出模块的其他配置项)来声明所需要的依赖,之后便会自动注入。看一个具体例子:
1 | //这里直接使用参数名声明所需要的依赖 |
这里也可以使用其他方法声明,如:
1 | module.exports = (a, b) => {} |
1 | module.exports = (a, b) => {} |
接着就是我们的依赖注入容器了:
1 | const fnArgs = require('parse-fn-args') |
和服务定位器不同的就是创建实例的地方,不是直接调用工厂函数,而是通过 inject 来自动获取某个模块所需要的依赖,并自动创建出依赖实例,然后将这些实例作为参数传递个这个模块的工厂函数。拿 authService 来说,取到 authService 的工厂函数的参数列表 [db, tokenSecret],然后就去取对应的这两个的实例,db 的实例取到 example-db 的数据块实例,tokenSecret 就直接取到了 SHHH!,然后再把取到的数据库实例和 SHHH! 作为参数传递给 authService 的工厂函数从而构造出 authService 的实例。
具体是使用 服务定位器 还是 依赖注入容器 就取决于你自己了,只是使用的方式不一样而已,都是用来实现控制反转的且都是基于模块本身是依赖注入的。
Wiring plugins(连接插件)
软件工程的架构都希望拥有一个最小功能,其他的功能通过插件来补充。但是会因为时间、资源、复杂度上的限制使得没有那么容易达成这个目标。尽管如此我们还是希望通过插件来扩展系统,我们关注两个问题:
- 将应用程序服务暴露给插件
- 将插件集成到应用程序中
Plugins as packages(包装插件成包)
通常来说插件会作为包安装到 node_modules 目录中。这样做有两个好处,首先,我们可以利用 npm 的功能来分发插件并管理它的依赖关系。其次,一个包可以有自己的私有依赖关系图,这样可以减少依赖关系之间发生冲突和不兼容的可能性,而不是让插件使用父项目的依赖关系。
有些插件是有状态的,因为插件有时候也需要用到父项目的一些服务。
Extension points(扩展点)
有很多种方法可以是的我们程序变得可扩展,例如代理模式、装饰者模式,而重要的是找到扩展点。
Plugin-controlled vs application-controlled extension(插件控制扩展 vs 应用控制扩展)
主要有两种方式去扩展一个应用的组件:
- 直接扩展
- 通过
IoC(控制反转) 扩展
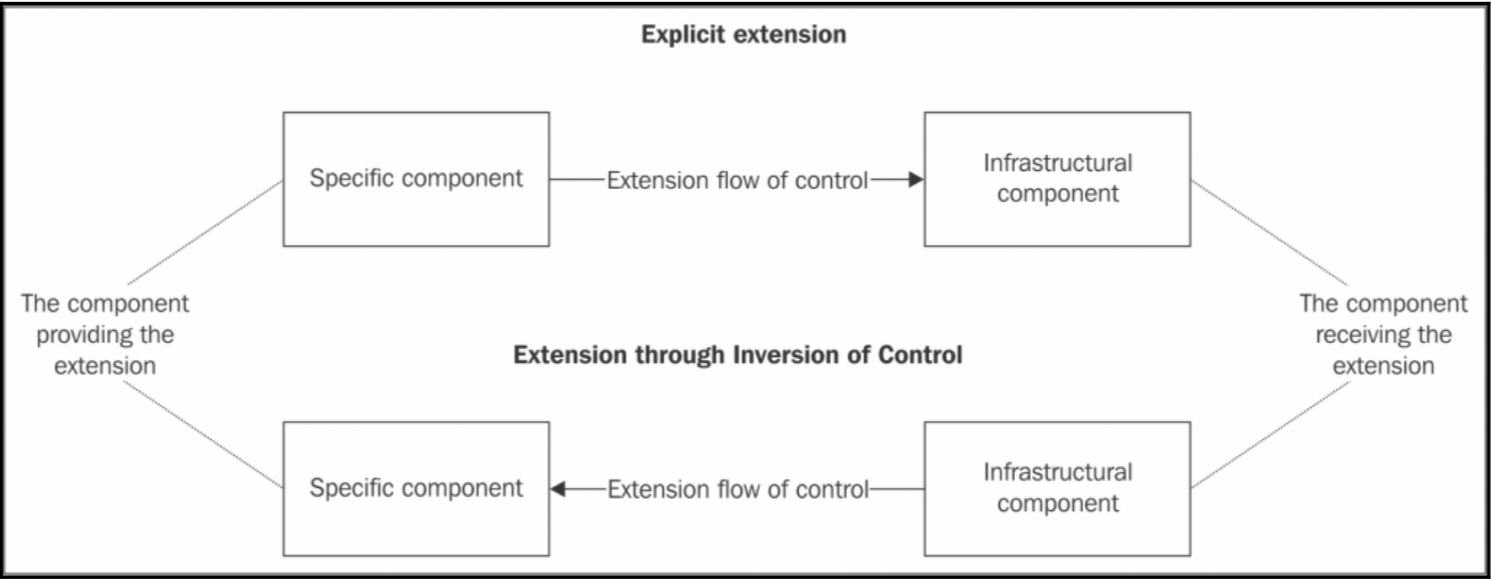
可以看到直接扩展就是一个特定组件直接控制基础设施,而第二种就是基础设施通过加载、安装、执行特定组件来完成控制扩展。
将这两种方法应用到插件就是 “插件控制扩展” 和 “应用控制扩展”了。
插件控制扩展例子,插件接收应用作为参数,然后对扩展点进行扩展:
1 | //in the application |
应用控制扩展例子,是直接在应用中使用 plugin 来扩展:
1 | //in the application |
两种方式的不同:
插件控制扩展更加强大和灵活,因为插件能获取到应用内部的内容,如果插件原来就是应用的一部分那么也是很容易抽离出插件的,不用更改多少的代码。但是这种方式可能有更多的不利,实际上,应用中的任何改动很容就间接影响到插件,使得插件得不断地更新。
插件控制扩展没啥要求,而应用控制扩展则需要插件具有一个基础结构(上面类似于
method,route,handler这些东西)。插件控制扩展必须得共享应用实例,否则就做不到扩展。而应用控制扩展可能只需要共享应用的一部分服务。
Implementing a logout plugin(实现一个日志插件)
Exposing services using a service locator(使用服务定位器暴露服务)
这就是使用插件控制扩展的实现。
1 | //plugin-logou/index.js |
1 | /** |
过程:注册 app 本身到服务定位器,因为插件可能需要用到 app 中的某些服务;引入插件;调用插件的主函数,服务定位器作为参数。
Exposing services using DI container(使用依赖注入容器暴露服务)
这就是使用应用控制扩展的实现。
1 | //plugin-logout/index.js |
1 | // ... |
这种情况下,可能插件在暗地里会使用各种各样的服务,存在潜在的危险,一个解决方案就是创建一个单独的依赖注入容器,一种只注册我们想要暴露的服务,这样我们就能控制插件所能看到的主应用的东西。这也解释了依赖注入容器可以很好地实现封装和信息隐藏。