
Advanced Asynchronous Recipes(高级异步方法)
Requiring aysnchronously initialized modules(引入异步初始化的模块)
第二章中我们了解到,require 是同步的,是不能异步更改 module.exports 的,所以很多核心模块都包含了同步的 API。但是有时候同步不一定有条件,例如在初始化的过程中需要请求网络获取某些参数,很多数据库、中间件(例如消息队列)等就是这种。
Canonical solutions(权威方案)
我们举一个例子:一个名为 db 的模块,它将会连接到远程数据库。只有在连接和与服务器的握手完成之后,db 模块才能够接受请求。在这种情况下,我们通常有两种选择:
- 在开始使用之前确保模块已经初始化,否则则等待其初始化。每当我们想要在异步模块上调用一个操作时,都必须完成这个过程:
1 | const db = require('aDb') //The async module |
- 另外一种就是依赖注入:
1 | // 模块app.js |
第一种依赖数量过多时不适用,而第二种会变得比较复杂。
Preinitialization queue(预初始化队列)
将模块与依赖项的初始化状态分离的简单模式涉及到使用队列和命令模式。这个想法是保存一个模块在尚未初始化的时候接收到的所有操作,然后在所有初始化步骤完成后立即执行这些操作。
Implementing a module that initializes asynchronously(实现一个异步初始化的模块)
1 | const asyncModule = module.exports |
调用方法时检查是否已经初始化(根据 initialized 变量判断),未初始化则抛出异常。
Wrapping the module with preinitialization queues(使用预初始化序列包装模块)
为了维护服务器的鲁棒性,我们现在要通过使用我们在本节开头描述的模式来进行异步模块加载。
1 | //asyncModuleWrapper.js |
In the wild(其他场景)
我们刚刚介绍的模式被许多数据库驱动程序和 ORM 库所使用。最值得注意的是 Mongoose,它是 MongoDB 的 ORM。使用 Mongoose,不必等待数据库连接打开,以便能够发送查询,因为每个操作都排队,稍后与数据库的连接完全建立时执行。这显然提高了其 API 的可用性。详情可看 Mongoose 源码。
Asynchronous batching and caching(异步批处理和缓存)
Implementing a server with no caching or batching(实现一个没有批处理和缓存的服务器)
考虑一个管理电子商务公司销售的 web 服务器,特别是对于查询我们的服务器所有特定类型的商品交易的总和的情况。为此,考虑到 LevelUP 的简单性和灵活性,我们将再次使用 LevelUP。我们要使用的数据模型是存储在 sales 这一个 sublevel 中的简单事务列表,它是以下的形式:
1 | transactionId {amount, item} |
key 由 transactionId 表示,value 则是一个 JSON 对象,它包含 amount,表示销售金额和 item,表示项目类型。要处理的数据是非常基本的,所以让我们立即在名为的 totalSales.js 文件中实现 API,将如下所示:
1 | const level = require('level') |
为了完成总销售应用程序,我们只需要从 HTTP 服务器公开 totalSales 的 API;所以,下一步是构建一个(app.js 文件):
1 | const http = require('http') |
Asynchronous request batching(批量异步处理)
如果请求相同的异步 API 并且输入相同,那么可以考虑批处理。如果我们在调用异步函数的同时还有另一个正在处理的相同请求,我们可以将这次的回调函数附加到已经运行的操作(也就是异步操作))上,而不是创建一个全新的请求。看下面这张图:
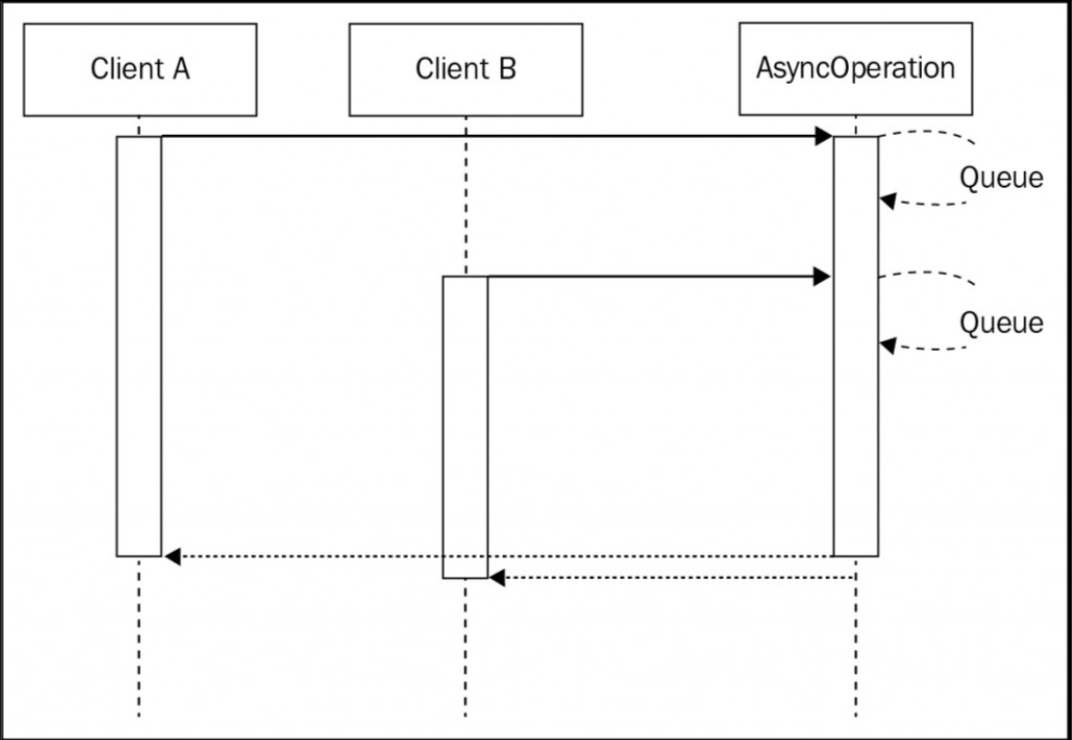
对两个请求执行到相同的操作。通过这样做,当操作完成时,两个客户端将同时被通知。这代表了一种简单而又非常强大的方式来降低应用程序的负载,而不必处理更复杂的缓存机制,这通常需要适当的内存管理和缓存失效策略。
Batching requests in the total sales web server(在销售总量 web 服务器中批量处理请求)
1 | const totalSales = require('./totalSales') |
- 如果请求的
item已经存在队列中,则意味着该特定item的请求已经在服务器任务队列中。在这种情况下,我们所要做的只是将回调push到现有队列,并立即从调用中返回。不进行后续操作。 - 如果请求的
item没有在队列中,这意味着我们必须创建一个新的请求。为此,我们为该特定item的请求创建一个新队列,并使用当前回调函数对其进行初始化。接下来,我们调用原始的totalSales()API。 - 当原始的
totalSales()请求完成时,则执行我们的回调函数,我们遍历队列中为该特定请求的item添加的所有回调,并分别调用这些回调函数。
Asynchronous request caching(异步请求缓存)
对于一个有经验的开发人员来说,缓存不应该是多么新的技术,但是异步编程中这种模式的不同之处在于它应该与批处理结合在一起,以达到最佳效果。原因是因为多个请求可能并发运行,而没有设置缓存,并且当这些请求完成时,缓存将会被设置多次,这样做则会造成缓存资源的浪费。
基于这些假设,异步请求缓存模式的最终结构如下图所示:
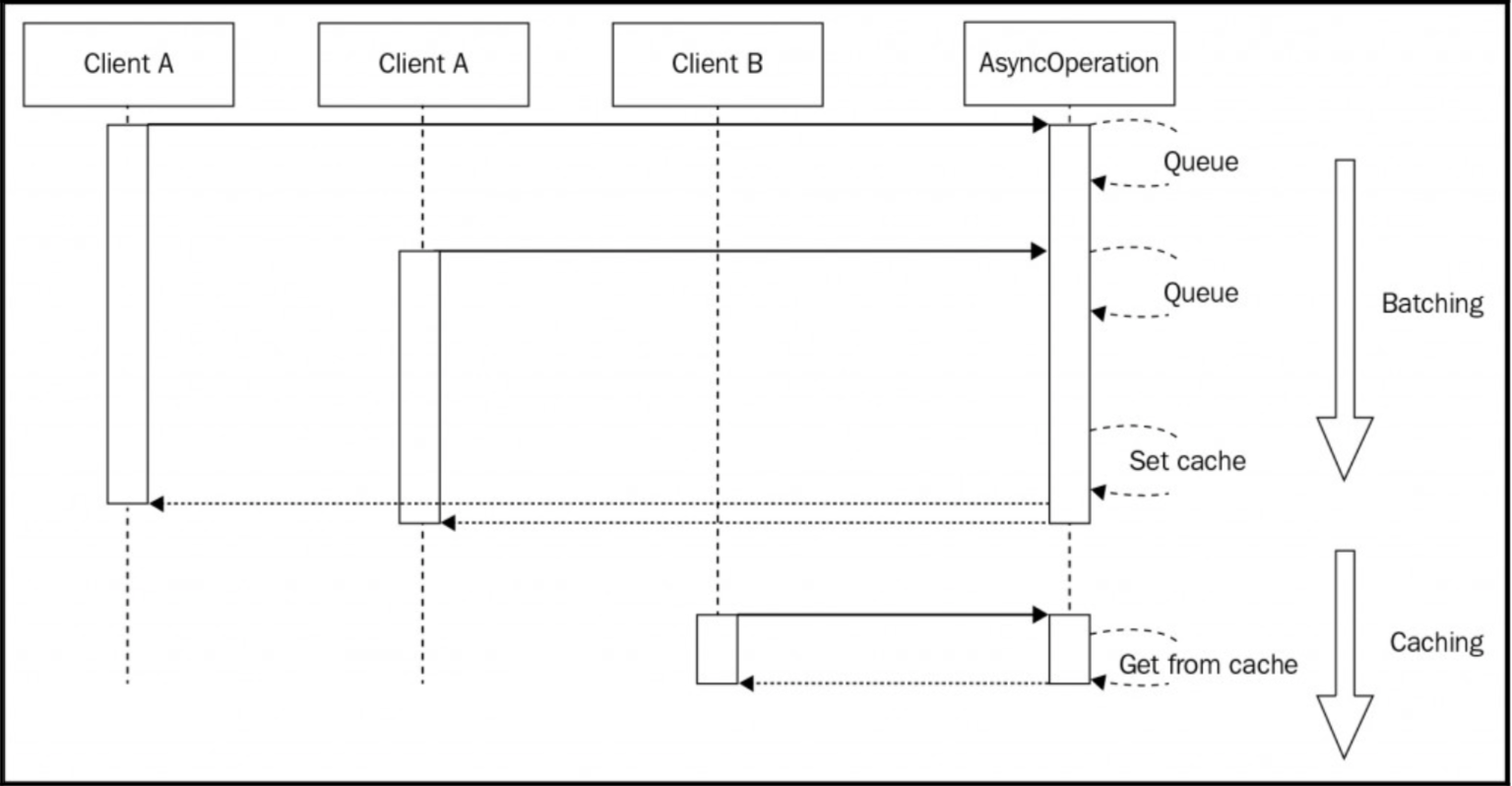
上图给出了最佳异步缓存算法的两个步骤:
- 与批处理模式完全相同,与在未设置高速缓存时接收到的任何请求将一起批处理。这些请求完成时,缓存将会被设置一次。
- 当缓存最终被设置时,任何后续的请求都将直接从缓存中提供。
Caching requests in the total sales web server(在销售总量 web 服务器中缓存请求)
1 | //totalSalesCache.js |
Notes about implementing caching mechanisms(有关缓存实现机制的说明)
我们必须记住,在实际应用中,我们可能想要使用更先进的失效技术和存储机制。 这可能是必要的,原因如下:
- 大量的缓存值可能会消耗大量内存。 在这种情况下,可以应用
Least Recently Used(LRU)算法来保持恒定的存储器利用率。 - 当应用程序分布在多个进程中时,对缓存使用简单变量可能会导致每个服务器实例返回不同的结果。如果这对于我们正在实现的特定应用程序来说是不希望的,那么解决方案就是使用共享存储来存储缓存。 常用的解决方案是
Redis(http://redis.io) 和Memcached(http://memcached.org)。 - 与定时淘汰缓存相比,手动淘汰高速缓存可使得高速缓存使用寿命更长,同时提供更新的数据,但当然,管理起缓存来要复杂得多。
Batching and caching with promises(使用 Promise 来批处理和缓存)
利用 Promise 进行异步批处理和缓存策略,有如下两个优点:
- 多个
then()监听器可以附加到相同的Promise实例。 then()监听器最多保证被调用一次,即使在Promise已经被resolve了之后,then()也能正常工作。此外,then()总是会被保证其是异步调用的。
1 | const pify = require('pify') |
Running CPU-bound tasks(运行 CPU 密集型任务)
当我们运行一个长时间的同步任务时,Node.js 会一直处于阻塞的状态,控制权不会还给事件循环,那么就无法处理多个请求了。
使用 setIntermediate
通常,CPU-bound 算法是建立在一定规则之上的。它可以是一组递归调用,一个循环,或者基于这些的任何变化/组合。所以,对于我们的问题,一个简单的解决方案就是在这些步骤完成后(或者在一定数量的步骤之后),将控制权交还给事件循环。这样,任何待处理的 I/O 仍然可以在事件循环在长时间运行的算法产生 CPU 的时间间隔中处理。对于这个问题而言,解决这一问题的方式是把算法的下一步在任何可能导致挂起的 I/O 请求之后运行。
最简单的方法就是使用 setIntermediate 来将控制权还给事件循环。
交错模式
正如我们所看到的,在保持应用程序的响应性的同时运行一个 CPU-bound 的任务并不复杂,只需要使用 setImmediate() 把同步执行的代码变为异步执行即可。但是,这不是效率最好的模式;实际上,延迟执行一个任务会额外带来一个小的开销,在这样的算法中,积少成多,则会产生重大的影响。这通常是我们在运行 CPU 限制任务时所需要的最后一件事情,特别是如果我们必须将结果直接返回给用户,这应该在合理的时间内进行响应。缓解这个问题的一个可能的解决方案是只有在一定数量的步骤之后使用 setImmediate(),而不是在每一步中使用它。但是这仍然不能解决问题的根源。
记住,这并不是说一旦我们想要通过异步的模式来执行 CPU-bound 的任务,我们就应该不惜一切代价来避免这样的额外开销,事实上,从更广阔的角度来看,同步任务并不一定非常漫长和复杂,以至于造成麻烦。在繁忙的服务器中,即使是阻塞事件循环 200 毫秒的任务也会产生不希望的延迟。在那些并发量并不高的服务器来说,即使产生一定短时的阻塞,也不会影响性能,使用交错执行 setImmediate() 可能是避免阻塞事件循环的最简单也是最有效的方法。
process.nextTick()不能用于交错长时间运行的任务。nextTick()会在任何未返回的I/O之前调度,并且在重复调用process.nextTick()最终会导致I/O饥饿。
使用多进程
防止事件循环阻塞的另一种模式是使用子进程。
Node.js 有一个充足的 API 库带来与外部进程交互。我们可以在 child_process 模块中找到我们需要的所有东西。而且,当外部进程只是另一个 Node.js 程序时,将它连接到主应用程序是非常容易的,我们甚至不觉得我们在本地应用程序外部运行任何东西。这得益于 child_process.fork() 函数,该函数创建一个新的子 Node.js 进程,并自动创建一个通信管道,使我们能够使用与 EventEmitter 非常相似的接口交换信息。
关于多进程的使用及如何通信和查看 Child Processes。