
Scalability an Architectural Patterns(可扩展性和架构模式)
An introduction to application scaling(应用扩展介绍)
Scaling Node.js applications(扩展 Node.js 应用)
我们知道 Node.js 是单线程的,得益于事件循环,我们可以使用单线程来处理成千上万的请求。假如我们的设备够好的话,那么单线程将成为性能瓶颈,尽管服务可以更强大。因此我们想要使用 Node.js 来开发高负载的应用程序,唯一的方法就是通过多进程、多设备来扩展。
The three dimensions of scalability(可扩展性的三方面)
谈到可扩展性,第一个原则就是负载分布,就是将服务分散在多个地方。《The Art of Scalability》一书中提到了 3 个维度:
- x 轴:克隆
- y 轴:按 服务/功能 分解
- z 轴:按数据分区分割
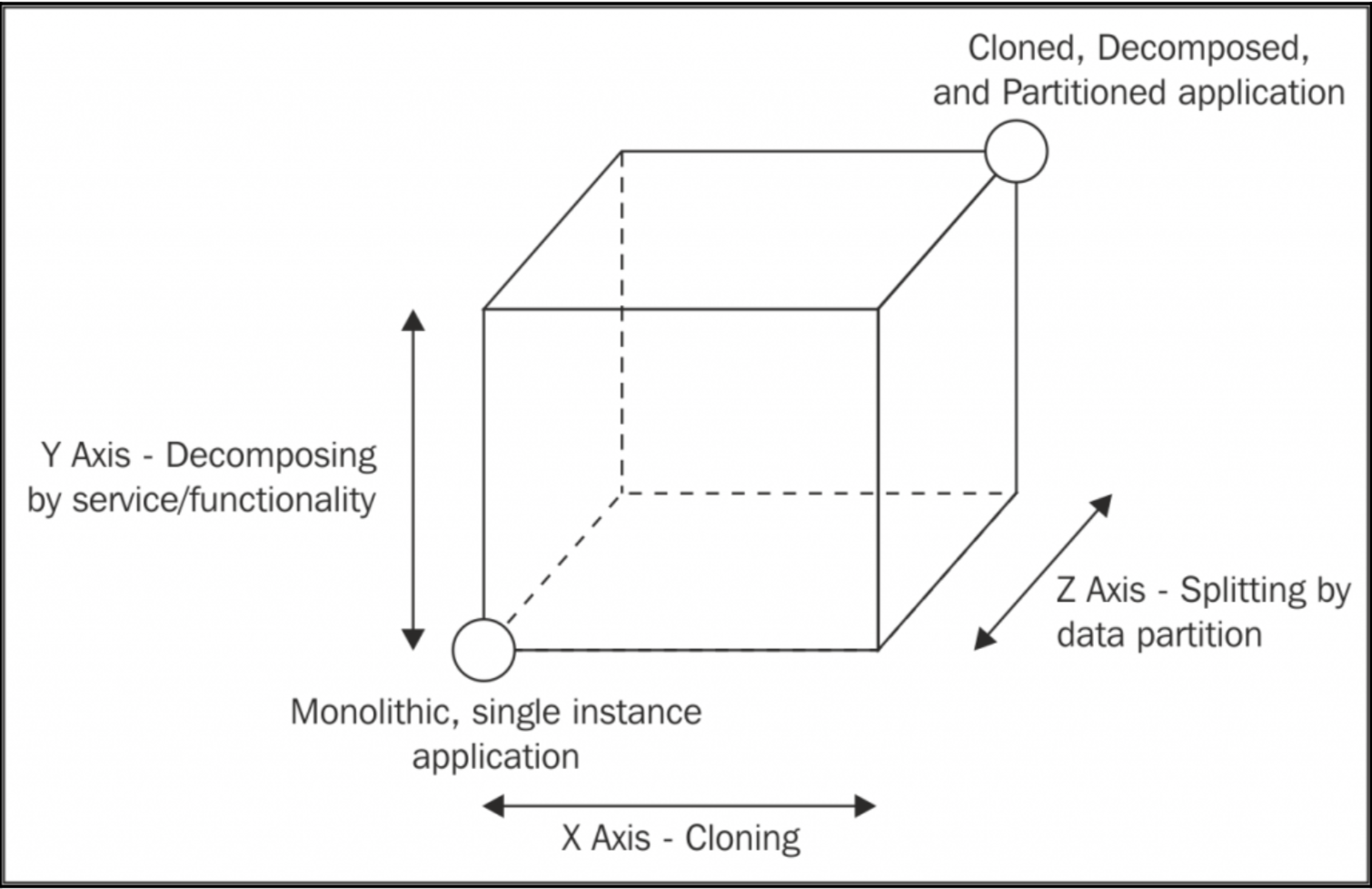
立方体的左下角代表那些所有服务都在一个地方的应用,并且只有一个实例。这是只有轻量负载应用的常用方案。
单例应用最直观的发展就是沿 x 轴向右平移,这是最简单,而且多数时候是廉价的(开发时间成本),而且高效。这个技术背后的原则是非常简单的,就是克隆实例 n 次,然后每个实例负责 1/n 的工作。
向 y 轴方向扩展意味着基于功能、服务和用例分解应用。在这种情况下,分解意味着创建不同的应用,它们有着自己的代码,甚至是数据库、UI。微服务就是在 y 轴上的扩展。
最后一个扩展维度是 z 轴,即每个实例只负责整个数据的一部分。这种主要应用于数据库,也就是水平分割或分片。
Cloning and load balancing(克隆和负载均衡)
传统的多线程 Web 服务器通常在分配给一台机器的资源不能再升级或者这样升级的代价要高于简单地启动另一台机器的时候进行扩展。使用多线程,传统的 Web 服务器能利用一个服务器的所有处理能力,比如说所有的处理器和内存。然而,一个单线程的 Node.js 应用是很难做到的,因为单线程在 64 位操作系统最多分配 1.7GB 的内存,这就意味着 Node.js 应用要比传统的服务要更快地去扩展,使得即使在单个机器的情况下也能利用所有的资源。
不要误认为这是一个缺点,相反在应用的其他质量属性上有很多优点,尤其是可靠性和容错性。
The cluster module(集群模块)
在 Node.js 中,分发负载的最简单的模式就是通过核心库的 cluster 模块在一台机器上运行多个实例。cluster 模块简化了拷贝相同应用实例并且自动分发来到的连接。
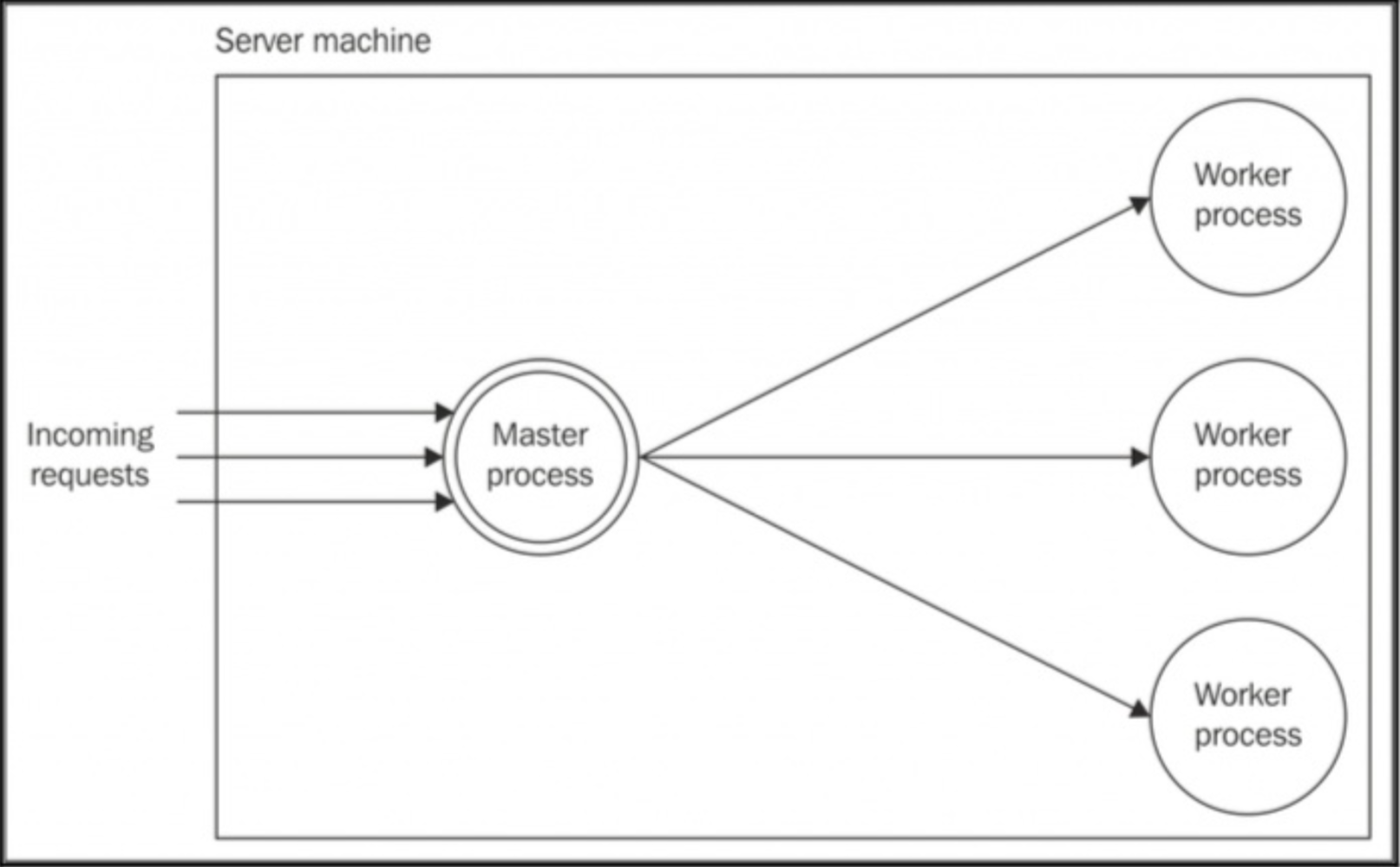
主进程负责产生若干个 workers,每一个 worker 都是我们想要扩展的应用的一个实例。每个来到的连接被分发到相应的 worker。
Notes on the behavior of the cluster module(cluster 模块的行为)
在 Node.js 0.8 和 0.10 中, cluster 模块在多个 worker 中共享相同的服务套接字,留给操作系统在可用的 worker 中对来到的连接负载均衡的任务。但是这种模式有个问题,操作系统在 workers 之间分配负载并不意味着网络请求的负载均衡,更像是调度进程的执行。但是在 0.12 版本以后就不同了,在主进程中有一个明确的循环负载均衡算法,使得请求在 workers 之间平均分布。新的负载均衡算法默认在除 Windows 外的其他平台外使用,并且可以通过设置变量 cluster.schedulingPolicy,常量 cluster.SCHED_RR 或 cluster.SCHED_NON 来修改。
Building a simple HTTP server(建立一个简单的 HTTP 服务)
1 | const http = require('http') |
我们可以测量服务器在一个进程的情况下每秒最多处理多少请求,比如使用网络基准测试工具像 siege 或 Apache ab。
1 | # siege |
上面的命令代表 200 个并发连接在 10s 内请求服务器。作为参考,一个有 4 个处理器的系统结果是每秒 90 个事务,CPU 的利用率仅仅为 20%。
Scaling with the cluster module(使用 cluster 模块来扩展应用)
1 | //clusterApp.js |
可以发现非常简单,当启动 clusterApp 时,运行主进程,并根据 CPU 数量使用 cluster.fork() 创建子进程。当进入子进程时,主模块再次运行,但是 cluster.isMaster 为 false,所以不会再次启动子进程。
每个
worker都是单独的进程,有着独立的存储空间和事件循环。
总结来说,可以统一成下面的写法:
1 | if (cluster.isMaster) { |
在底层,cluster 模块使用了 child_process.fork() 的 API,因此在 master 与 worker 之间可以有一个可用的通信通道,worker 的实例可以通过 cluster.workers 来访问,向所有 worker 发送消息:
1 | Object.keys(cluster.workers).forEach(id => { |
在此运行度量命令:
1 | sieg -c200 -t10s http://localhost:8080 |
作为参考:有着 4 个处理器的
Linux系统中使用Node.js6 在CPU平均负载为 90% 的情况下,性能提升了 3 倍。
Resiliency and availability with the cluster module(cluster 模块的弹性和可用性)
当只有一个实例时,如果服务器宕机就会有一段时间不可用。而集群模式则可以避免这种情况:
1 | if (cluster.isMaster) { |
可以看到上面的代码在一个 worker 实例出现错误而崩溃时,会重新启动一个新的 worker。
Zero-downtime restart(零宕机时间重启)
当代码需要更新时,Node.js 应用程序也要重启,所以这种情况下,多实例可以帮助维护应用程序的可用性。
当我们不得不更新时,应用程序会在更新的这段时间里不可用,而解决方案就是在更新代码事零宕机时间重启来维护应用程序的可用性。cluster 模块可以只重启一个 worker,而其他 worker 继续工作:
1 | if (cluster.isMaster) { |
工作原理就是:
- 收到
SIGUSR2信号时开始迭代重启worker,只有当前面一个woker重新监听后才开始下一个worker重启。 restartWorker第一个任务就是通过worker.diconnect()来优雅地停止worker。接着在终止的进程结束时启动一个新的worker。
我们的程序使用的是
UNIX信号,所以在Windows系统上是不能正常运行的。信号是实现我们解决方案的最简单的方法,但也不是唯一的,比如还可以使用socker、管道等等。
其实零宕机时间重启 pm2 已经能帮我们做了,具体的使用方法可以移步 Node 服务部署。
Dealing with stateful communications(处理有状态通信)
cluster 模块是不适用于有状态通信的应用的,在不同的实例间状态不是共享的。这是因为属于同一个状态的会话发出的请求可能会被不同的应用实例处理,这不仅仅是 cluster 模块的问题,通常来说也是无状态负载均衡算法的问题。
Sharing the state across multiple instances(在多实例见共享状态)
要实现这个目的必须使用有状态通信来扩展应用程序,比如可以通过共享数据存储轻松地实现,像 PostgreSQL、MongoDB、CouchDB,或者是内存存储 Redis、Memcached。就像下面图中所示:

支持有状态通信的另外一种方式就是将同一个会话的请求总是分发到同一个实例上。这种技术被称为粘性负载均衡。
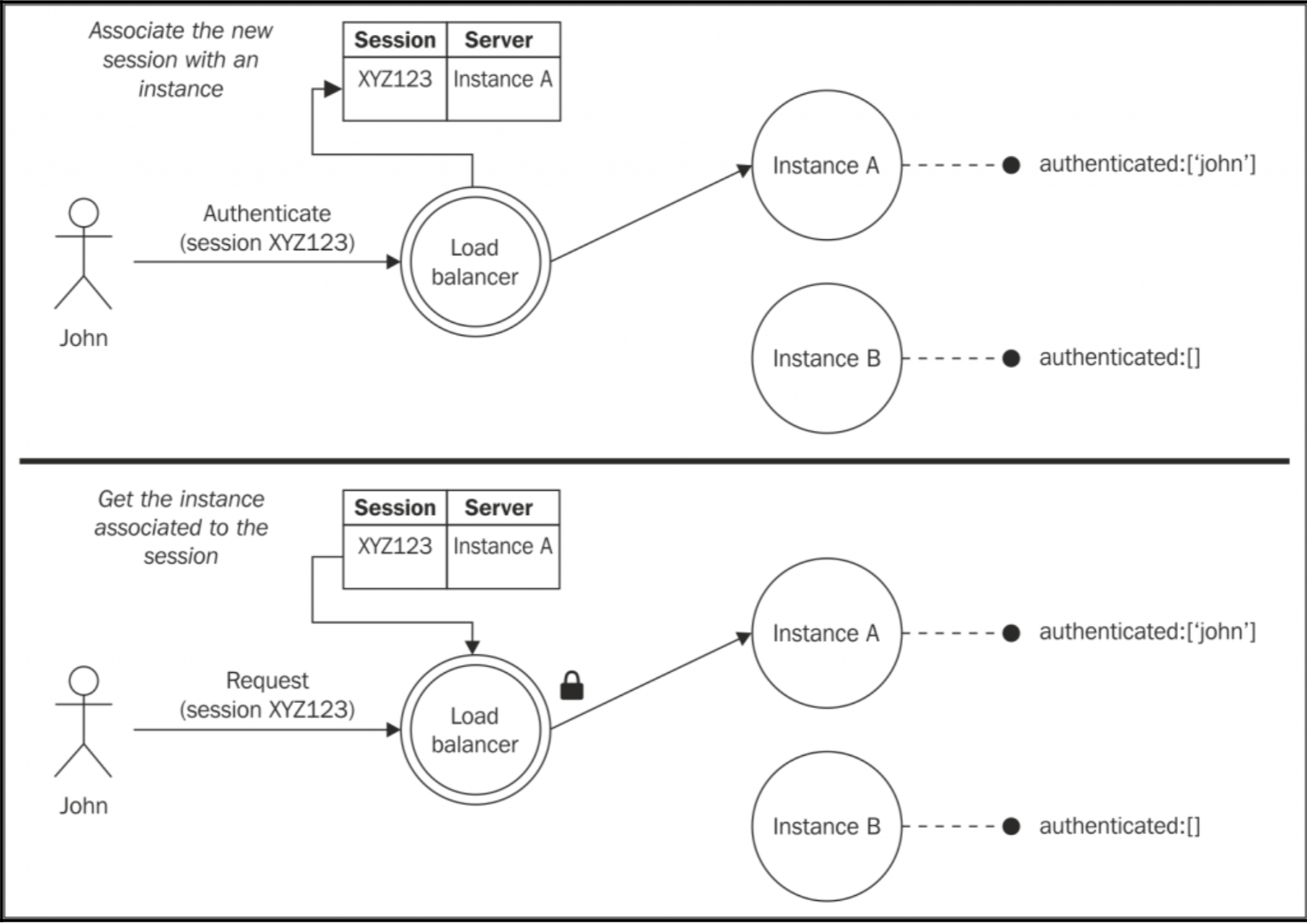
可以看到当接收到与会话相关的请求时,会创建一个由负载均衡算法选择的实例映射表。当下次负载均衡器接收到同一个会话请求时就会将该请求分发到同一个实例。这个技术相关的就是请求的 sessionID(通常在应用的 cookie 中)。
而更简单的办法就是通过 IP 地址来映射请求与处理的实例,这种技术的优点就是不需要负载均衡器记住关联,只需要通过 hash 就可以知道应该把请求分发到哪一个实例。但是对于会频繁更换 IP 的设备来说就是去了作用。
cluster 模块默认是不支持粘性负载均衡的,但是可以通过引入 sticky-session 来添加这个功能。
粘性负载均的一个大问题就是会使得冗余系统的一些优势不复存在,因为原来每个实例都是相同的,可以互相替代的(在一个宕机后另一个可以处理相同的请求),但是使用粘性负载均衡后就不行了。所以要尽量避免粘性负载均衡的使用,更多情况还是希望将会话状态存储在一个共享存储中或者根本不需要有状态通信。
Scaling with a reverse proxy(使用反向代理扩展)
cluster 不是扩展 Node.js 应用的唯一选择,还有很多传统的技术是首选,因为它们在生产环境中更容易使用。
替代 cluster 的另一种方法是在不同的端口启动同一个应用程序的多个独立实例,然后使用反向代理(或网关)提供对这些实例的访问权限,从而将流量分配到这些实例。
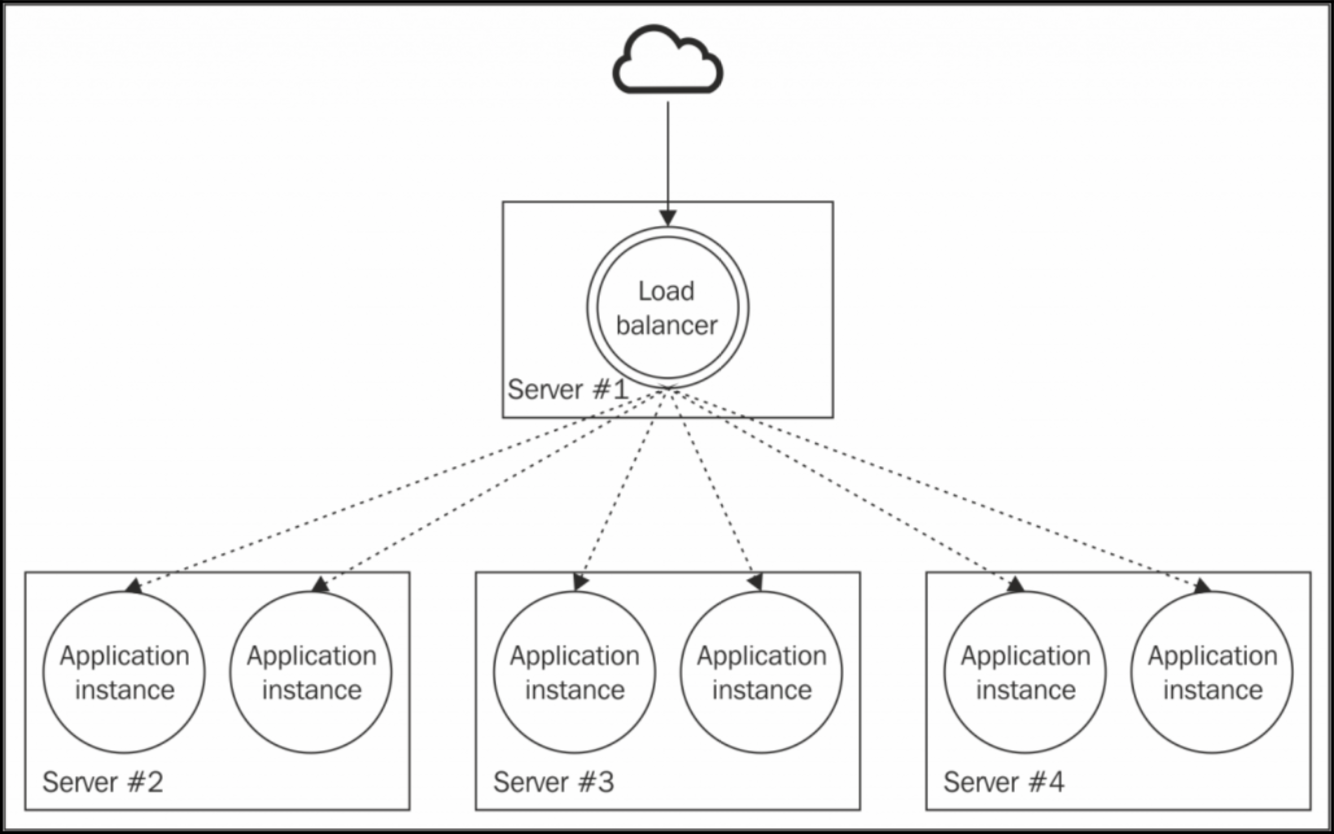
选择反向代理的原因有很多:
- 反向代理不仅仅可以将负载分布到多个进程,也可以分布到多个机器。
- 市场上最流行的反向代理支持粘性负载均衡。
- 反向代理可以任意路由,不管编程语言和平台。
- 可以选择更强大的负载均衡算法
- 许多反向代理还提供其他服务,如
URL重写、缓存甚至是完全成熟的Web服务器功能,例如为静态文件提供服务。
也就是说,如果需要,cluster 模块也可以结合反向代理使用:使用 cluster 在单个机器内垂直扩展,而使用反向代理在不同节点之间水平扩展。
使用反向代理实现负载均衡有很多种选择,其中比较流行的有:
- Nginx,一个基于非阻塞
I/O的Webp服务器、反向代理、负载均衡器。 - HAProxy,一个用于
TCP/HTTP流量的快速负载均衡器。 - 基于
Node.js的代理。 - 基于云的代理服务器。
Load balancing with Nginx(使用 Nginx 进行负载均衡)
1 | const http = require('http') |
使用 pm2 来启动多个应用实例:
1 | pm2 start app.js 8081 |
接着配置 Nginx 负载均衡,找到 nginx.conf(一般在 /usr/local/etc/nginx),并配置:
1 | http { |
在 upstream nodejs_design_patterns_app 中定了用于处理网络请求的后端服务器列表,在 server 部分中指定了 proxy_pass,告诉 Nginx 将任何而请求转发给我们之前定义的服务器组。然后重新加载 Nginx 配置:
1 | nginx -s reload |
Using a service registry(使用服务注册)
基于云的基础架构的一个重要优势就是能够基于当前的运行情况,预测的流量动态调整应用的容量。该机制要求负载均衡器随时了解当前的网络拓扑结构,随时了解哪台服务器处于运行状态。解决此问题的常见模式就是使用成为服务注册中心的中央存储库,该中心存储库跟踪正在运行的服务器及其提供的服务。
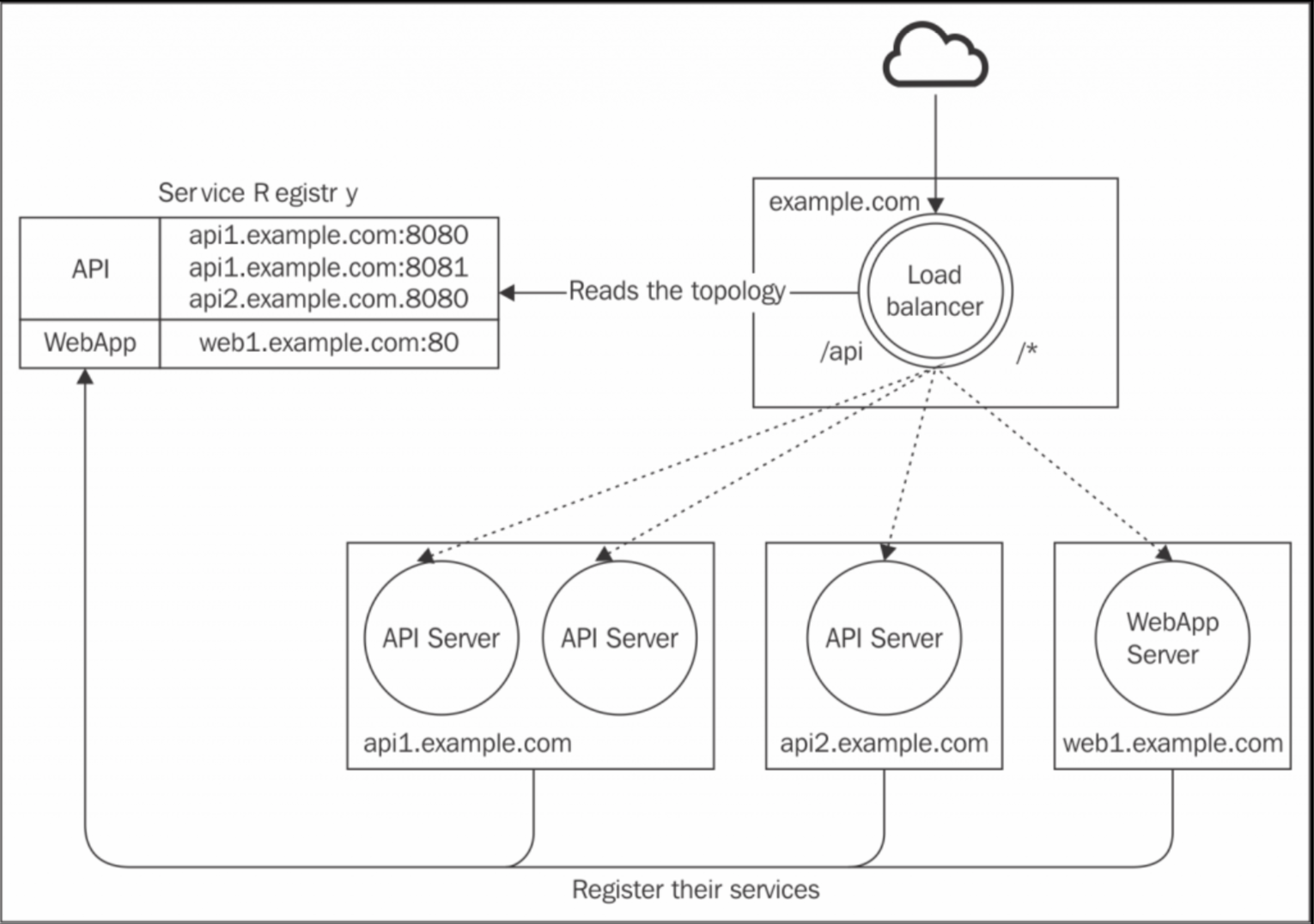
上述架构假定存在两个服务 API 和 WebApp,负载均衡器将到达 /api 节点的请求分发给实现 API 服务的所有服务器,而其于请求分布在实现 WebApp 服务的服务器上。这点和微服务架构是一样的,同样的也是需要将自己注册到服务中心,在停止时取消注册,这样负载均衡器可以使用拥有最新的服务器视图和网络上可用的服务。
Implementing a dynamic load balancer with http-proxy and Consul(使用 http-proxy 和 Consul 来实现动态负载均衡器)
为了支持动态网络,我们可以使用诸如 Nginx 或 HAProxy 的方向代理,我们要做的只是使用自动服务更新它们的配置,然后强制负载均衡器使用新配置。对 Nginx 来说,可以 nginx -s reload 即可。
这个例子使用 Consul 来作为服务注册。并使用下面 3 个 npm 包:
- http-proxy,一个简化代理和负载均衡的库。
- portfinder,一个发现系统空闲端口的库。
- consul,一个允许服务注册的库。
服务注册的代码:
1 | // app.js |
上面代码的逻辑:
- 首先使用
portfinder.getPort找到可用的端口(默认从 8000 端口开始查找)。 - 然后使用
Consul库在注册表中注册一项新服务。服务定义需要几个属性,id(服务的唯一名称),name(标识服务的通用名称),address和port(用于标识如何访问服务),tags(一个可选的标签列表,可以用来过滤和组合服务),serviceType(作为命令行参数制定服务名称并添加标签,这将允许我们识别集群中可用的相同类型的所有服务)。 - 定义了
unregisterService函数,它移除我们刚刚在Consul中注册的服务。 - 使用
unregisterService作为一个清理函数,所以当程序关闭时(人为或意外),服务会从Consul中移除。 - 最后在我们发现的端口上启动
HTTP服务。
现在可以去实现负载均衡器了,定义一个路由表将 URL 映射到对应的服务:
1 | // loadBalancer.js |
再来实现 loadbalancer.js 的第二部分:
1 | const http = require('http') |
- 首先引入
consul库,以便可以访问注册表。接着初始化http-proxy,并启动一个普通的Web服务器。 - 服务器处理请求的第一件事就是找到在路由表里匹配
URL的服务,将结果(包含服务的描述)赋值给route以供后续使用。 - 从
consul中拿到实现了需要服务的列表。如果列表为空,返回网关错误;否则使用Tag属性来过滤可用的服务,并且找到实现了当前服务类型的服务的地址。 - 最后,将请求路由到它的目的地。我们根据循环算法更新
route.index以指向列表的下一个服务器,以实现负载均衡,然后将它与请求(req)和响应(res)对象一起传递给proxy.web()。这将简单地将请求转发到我们选择的服务器。
启动服务并注册到 consul:
1 | # 在上面可以看到第二个参数为服务的名称 |
这样就完成了动态负载均衡了,真的很像微服务了(只不过是横向的,扩展实例而不是扩展功能)。
Peer-to-peer balancing(点对点负载均衡)
当我们想要讲一个复杂的内部网络架构暴露给公共网络时,使用反向代理是必须的。它有助于隐藏复杂性,提供外部应用程序可轻松使用和依赖的单一访问点。但是如果我们需要扩展仅供内部使用的服务器,则我们可以拥有更多的灵活性和控制力。
假设服务 A 依靠服务 B 来实现其功能,服务 B 在多台机器上有扩展,并且只能在内部网络中使用。服务 A 可以使用反向代理连接到服务 B。但是还有一种选择,就是删除反向代理,并直接从客户端(服务 A)分发请求,直接使用客户端实现负载均衡,这样来基本实现点对点负载均衡(peer-to-peer balancing)。
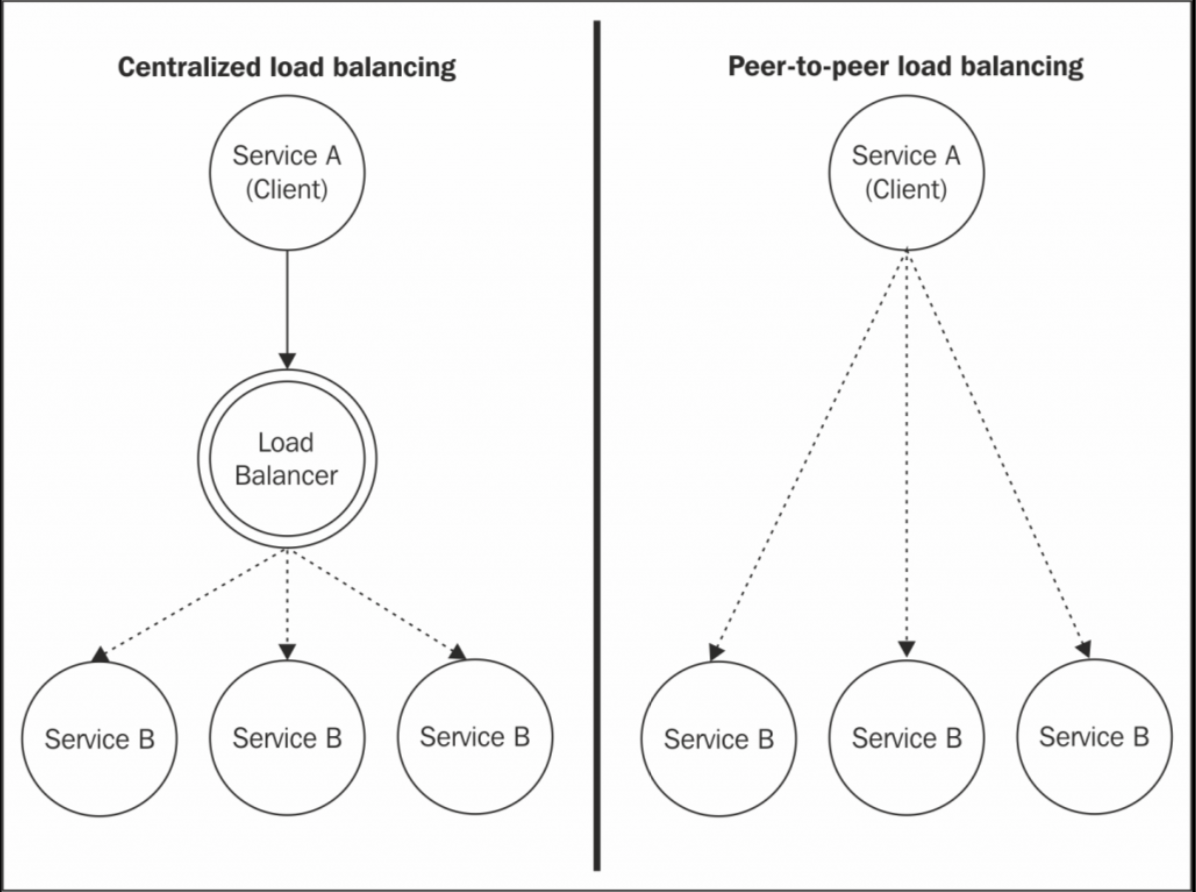
这是一种非常简单而有效地模式,来真正实现分布式通信,而不会出现瓶颈或者单点故障,除此之外还有以下几个优点:
- 通过删除网络节点来降低基础设施的复杂性。
- 更快的通信,因为消息经过更少的节点。
- 扩展性更好,因为性能不受负载均衡器可以处理的限制。
另一个方面,通过删除反向代理,我们实际上暴露了其底层基础架构的复杂性。此外,通过实施负载均衡算法,每个客户端都变得更加智能,并且也是保证基础架构是最新的一种方式。
点对点负载均衡是 ØMQ 库中广泛使用的一种模式。
Implementing an HTTP client that can balance requests across multiple servers(实现可跨多台服务器平衡请求的 HTTP 客户端)
我们已经知道了怎么仅仅使用 Node.js 来实现一个负载均衡器并且给可用的服务分发请求了,所以在客户端实现相同的机制并没有什么不同。
1 | // balancedRequest.js |
可以看到非常简单,只要将即将发出的请求用一个简单的循环算法分发就可以了。
同样的,也可以在客户端集成一个服务注册中心,然后动态地获得可用服务列表。
Decomposing complex applications(分解复杂应用)
前面都是说的在 x 轴上的扩展,现在谈谈 y 轴上的扩展,应用根据功能、服务来分解。
Monolithic architecture(单体架构)
单体架构就是所有的服务都集中在一起,但是内部也可以有着高度模块化的划分。像 Linux 操作系统的内核一样,就是单体架构的一类,它有着成百上千的可以在系统运行时装载和卸载服务和模块。然而他们都是在内核模式下运行的,意味着任何一个模块挂掉都会导致整个系统崩溃。这个和微内核架构是相反的,微内核架构就是仅仅核心的服务是在内核模式下运行,其他的是在用户模式下运行的,这种模式的好处就是一个服务的问题不会影响整个系统的稳定性。
值得注意的是,这些设计模式虽然有着 30 年的历史,但是如今仍被应用着。现代化单体应用和单体内核差不多,比如 Node.js,所有的服务都是基于相同的代码并在单进程中运行(没有克隆的时候)。
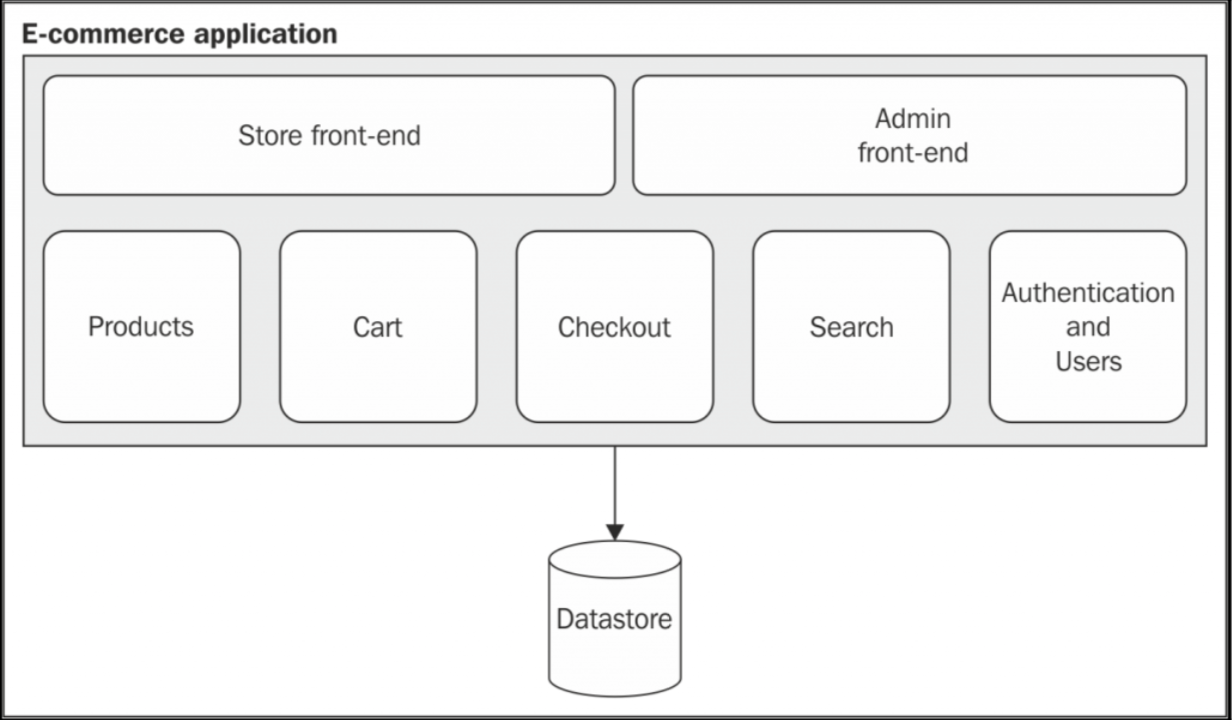
上图展示了一个电子商务的架构,它的结构是模块的,有两个不同的前端,一个是主商店使用,一个是管理员使用。所以这种情况下任何一个模块出了问题,整个系统都会瘫痪。
除此之外,高度耦合也是这种架构的一个问题,维护任何一个模块都会变得十分困难,可能修改一个模块会导致其他模块也需要修改,浪费大量时间,增加了系统的复杂度。
The microservice architecture(微服务架构)
现在我们要揭露在 Node.js 中编写大型应用最重要的模式了:阻止大应用。毋庸置疑这将降低系统的复杂度和提高系统的承受能力。这个模式的想法就是将系统按照功能、服务分解成独立的应用程序。和单体架构是完全相反的,这很好地适用 Unix 生态和开头的 Node.js 原则——“让每个程序做好一件事”。
微服务架构在今天应该是最好的这种模式的参考了,实现了高内聚、低耦合并整合了复杂性。
微服务的一个例子:
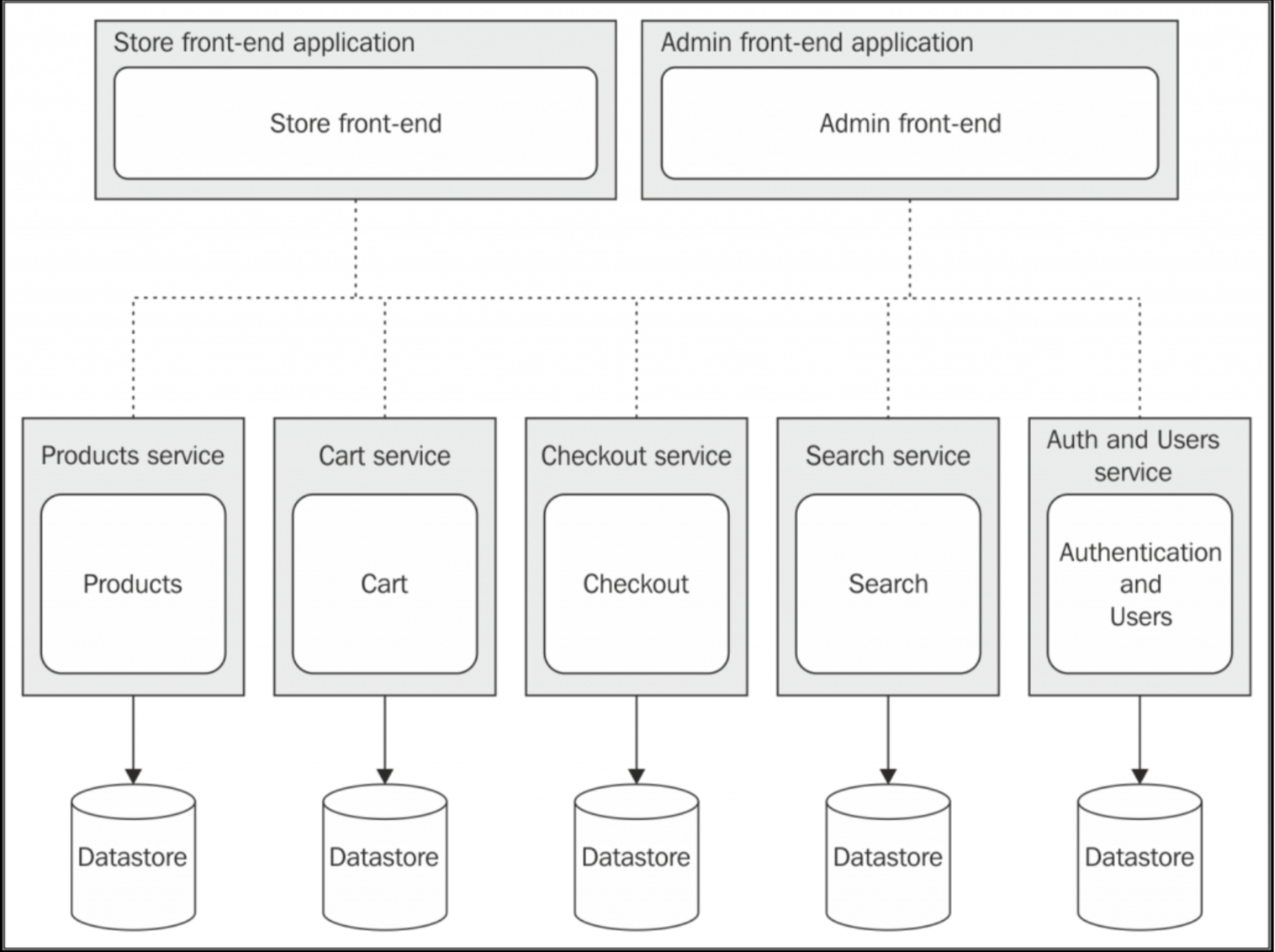
可以看到每个模块都单独地作为一个服务,有着自己的上下文和数据库。实际上,它们就是独立的应用程序,并暴露了相关的服务而已。
可以看到数据的拥有者是微服务架构的一大特点,虽然多个服务共享一个唯一的数据库会更容易让服务协同合作,但是却损失了多应用的一些优点。而使用不同的数据库又要考虑到数据的一致性。
微服务的优缺点
Every service is expandable(每个服务都是可扩展的)
最主要的优点就是每个服务都是在自己的上下文中运行,所以崩溃、bug、意外中断都不会影响整个系统。这个目标就是去构建更小的、更容易更改的独立服务。
Reuability across platforms and languages(扩平台、语言的可复用性)
将大系统分解成小服务以创建独立的单元使得复用变得更容易了。Elasticsearch 就是一个非常好的重用搜索服务的例子。
A way to scale the application(扩展应用的一个方式)
根据扩展立方体可以看到微服务就是在 y 轴上扩展了应用。同时我们也可以结合其他两个方向上的扩展,例如可以在不同的机器上部署相同的服务。
The challenges of microservices(微服务的挑战)
虽然看起来微服务解决了我们所有的问题,但是远远不是这样的。实际上,还有很多我们需要解决的问题。比如我们怎么让服务互相交流?怎么部署?怎么扩展?怎么监视一个巨大数量的应用?怎么在服务之间共享和复用代码?幸运的是,云服务和现代化的 DevOps 可以解决上面的一些问题,并且 Node.js 也可以帮助很多。模块化系统就可以很好地帮助我们在不同项目中共享代码。
Integration patterns in a microservice architecture(在微服务架构中的集成模式)
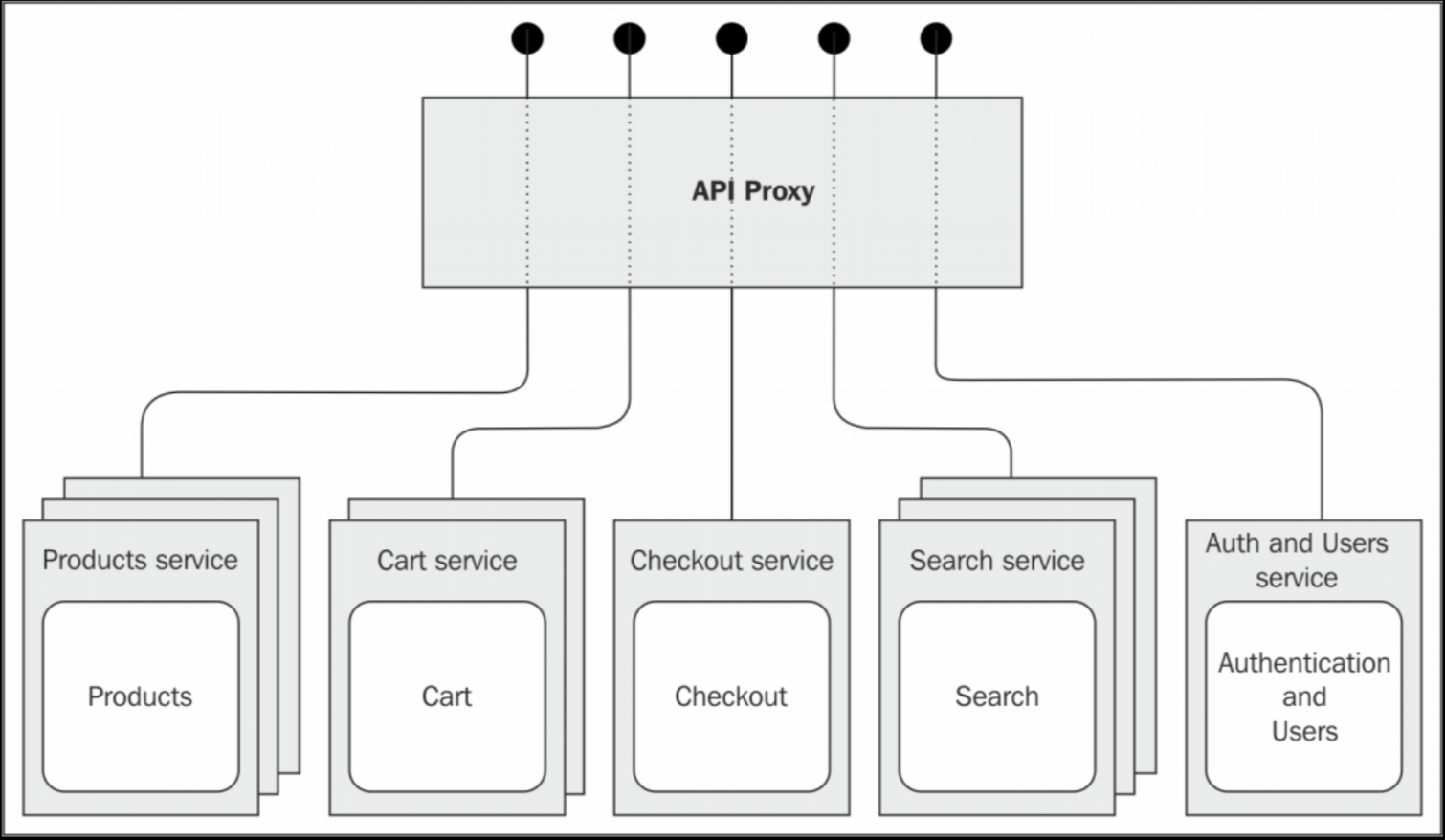
The API proxy(API 代理)
第一个我们要展示的模式就是利用 API 网关了,一个代理客户端和一系列远程 API 之间交流的服务。可以提供负载均衡、缓存、认证、流量控制等等功能。
API orchestration(API 编排)
下面要说的模式是最常见、最准确的集成和组合服务的方式,被称为 API orchestration(API 编排)。详情查看 The future of API design: The orchestration layer
。
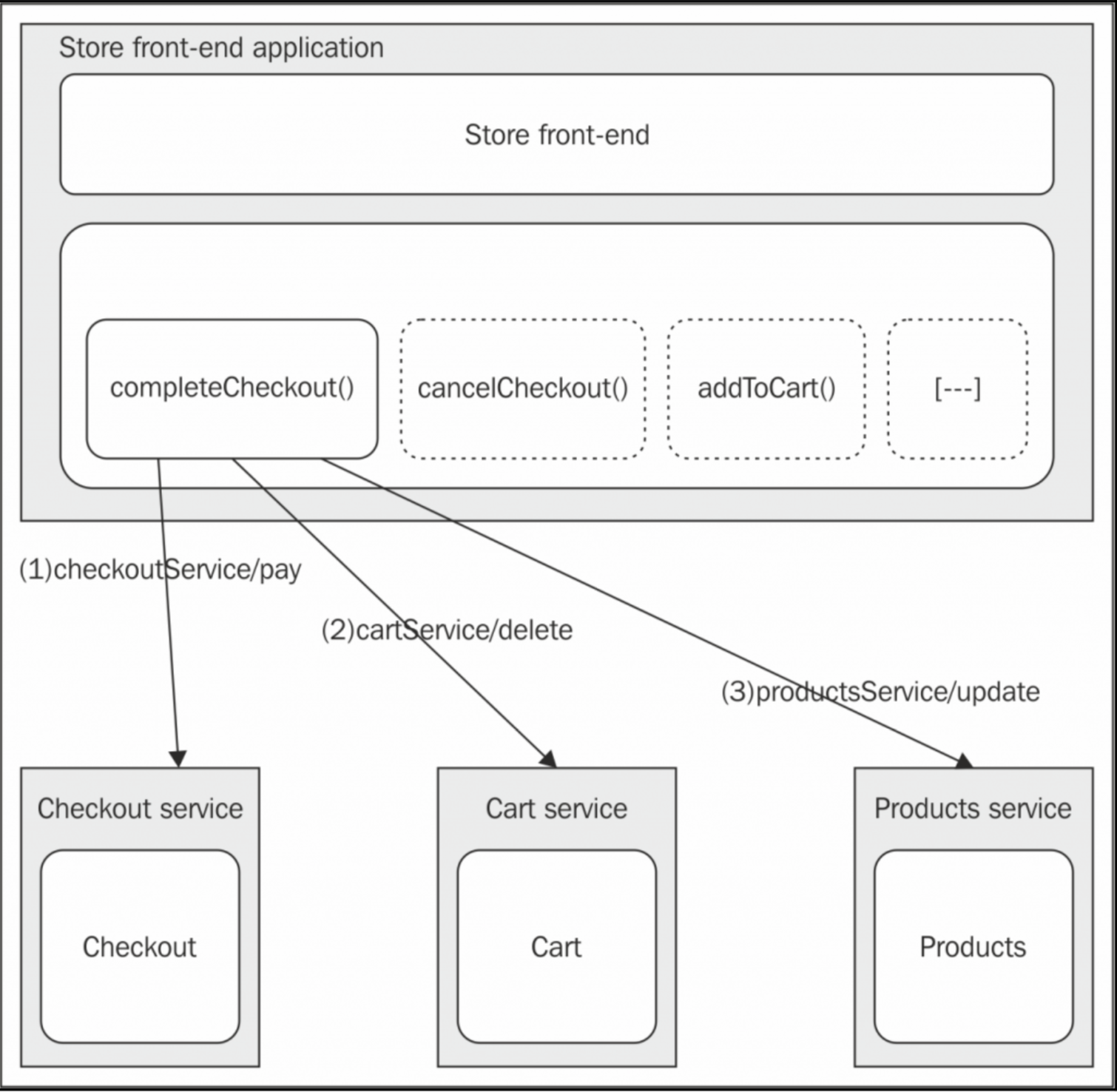
上面的图展示了商店前端应用是怎么使用一个编排层来通过组合和编排已经有的服务去构建更负责、确切的功能。假设 completeCheckout() 服务会在消费者在检查完后按下 Pay 这个按钮后触发,这张图展示了 completeCheckout() 是一个三个步骤组成的操作:
- 第一步,调用
checkoutService/pay来完成事务。 - 第二步,当已经成功付款后,我们需要告诉购物车服务那些商品已经被购买了,需要从购物车中移除,通过调用
cartService/delete来完成。 - 同时,当付款完成后,我们需要更新商品的可购买数量,使用
productService/update来完成。
可以看到我们通过组合了一系列操作来构建另一个新的 API,来在一个一致性的状态下通过协同各个服务来维护整个系统。可以单独地为 API 编排 创建一个层,来解耦客户端程序,降低微服务架构的复杂度,这个和 API 网关 很像,但是它不仅仅是一个简单的代理,通常还暴露了与基本服务提供的 API 不同的 API。
Integration with a message broker(集成一个消息代理)
编排模式概率我们一个已特定方式组合若干个服务的机制。它有它的优点,也有缺点。它容易设计、容易调试、容易扩展,但是又需要对整个架构有个清楚地认识,对每个服务怎么工作要了解。可以发现,orchestration 层知道了且做了太多东西了,导致了高耦合、低内聚、高复杂度。
接下来我们要讲的模式就解决了 API 编排 带来的问题,可以不用知道各个服务的细节就能同步系统的信息,解决方案就是使用一个消息代理,实现一个中心化的 “发布/订阅” 模式。
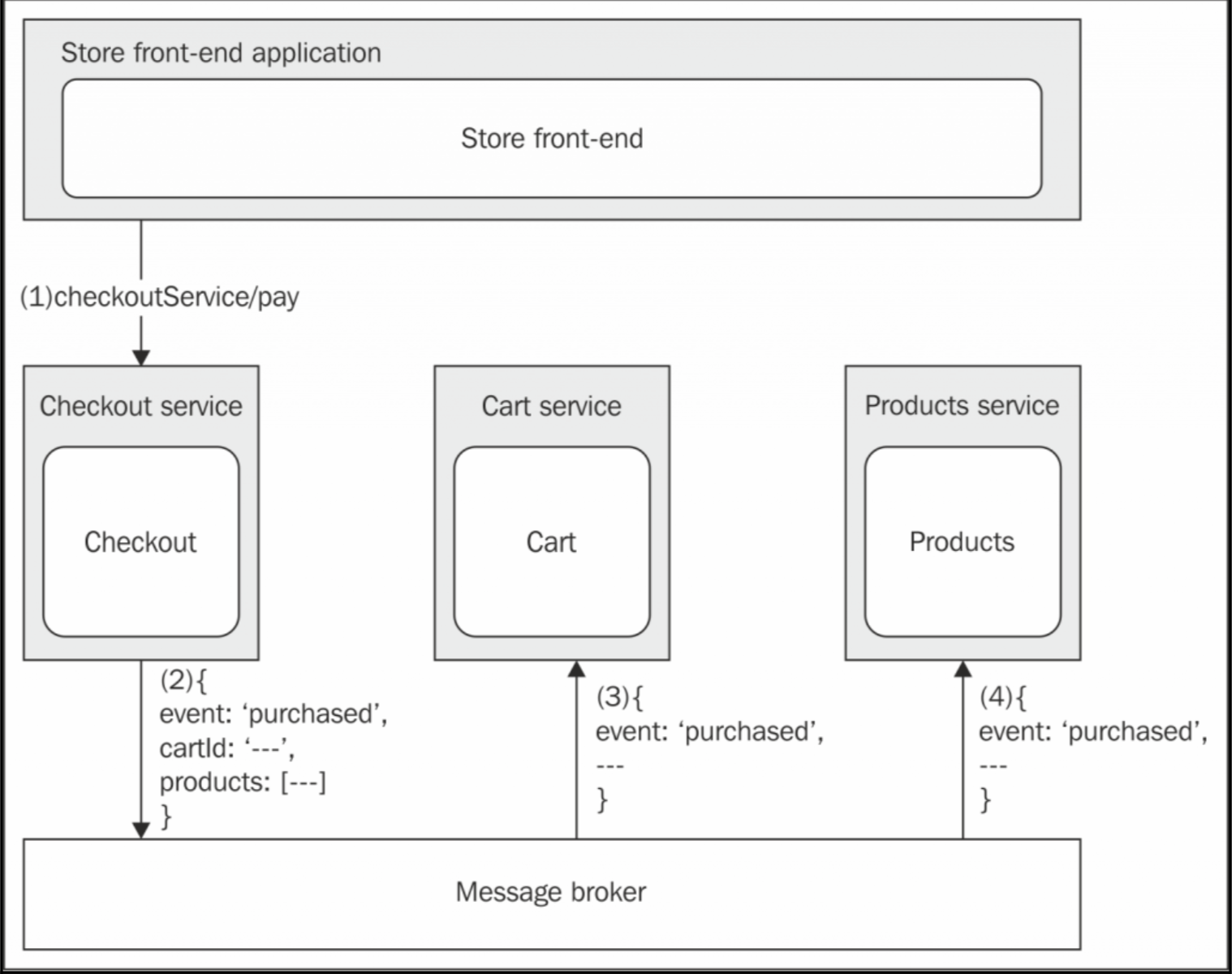
可以发现,现在 Checkout 服务只用管自己的事情了(检查清单并从消费者取走钱),其他集成的工作都是在后台做了:
- 商店前端通过
Checkout服务调用checkoutService/pay操作。 - 当操作完成时,
Checkout服务生成了一个包含了该操作细节的事件,cartId和购买的商品列表。这个事件被发布到消息代理中,Checkout服务并不知道谁会收到这条消息。 Cart服务向消息代理订阅了这类事件,所以它会受到Checkout服务发出的购买事件,然后根据携带的cartId和商品列表清空购物车。- 同样的,
Products服务也订阅了该类事件,然后收到消息,更新商品的库存。
可以看到这种模式大大降低了系统的耦合度,并且能完成消息的同步,同时也降低了复杂度。消息代理也可以提供其他有意思的功能,例如持久的消息队列,保证消息到来的顺序等。